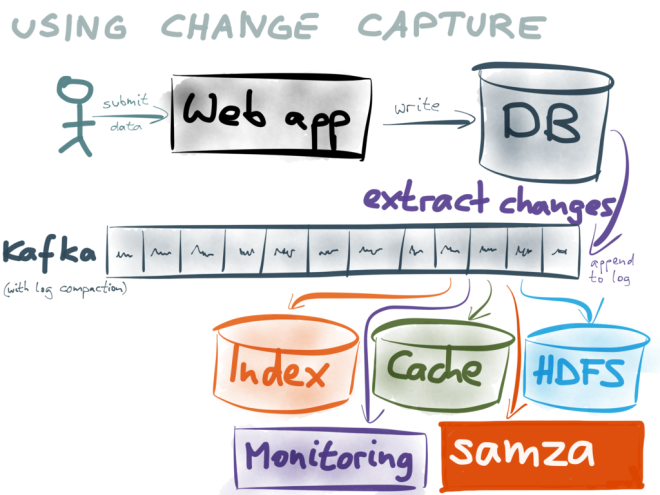
背景
在主流的OLTP数据库产品中,毫无疑问,PostgreSQL已经具备非常强大的竞争力(性能、功能、稳定性、成熟度、案例、跨行业应用等)。
通过这些文章我们可以了解更细致的情况。
《数据库十八摸 - 致 架构师、开发者》
《数据库界的华山论剑 tpc.org》
《PostgreSQL 前世今生》
在OLAP领域,PostgreSQL社区也是豪情万丈的,比如内核已经实现了基于CPU的多核并行计算、算子复用等。
在社区外围的插件如 GPU运算加速、LLVM、列存储、多机并行执行插件 等也层出不穷。
虽然如此,PostgreSQL在OLAP领域还有非常巨大的提升潜力。
![pic]()
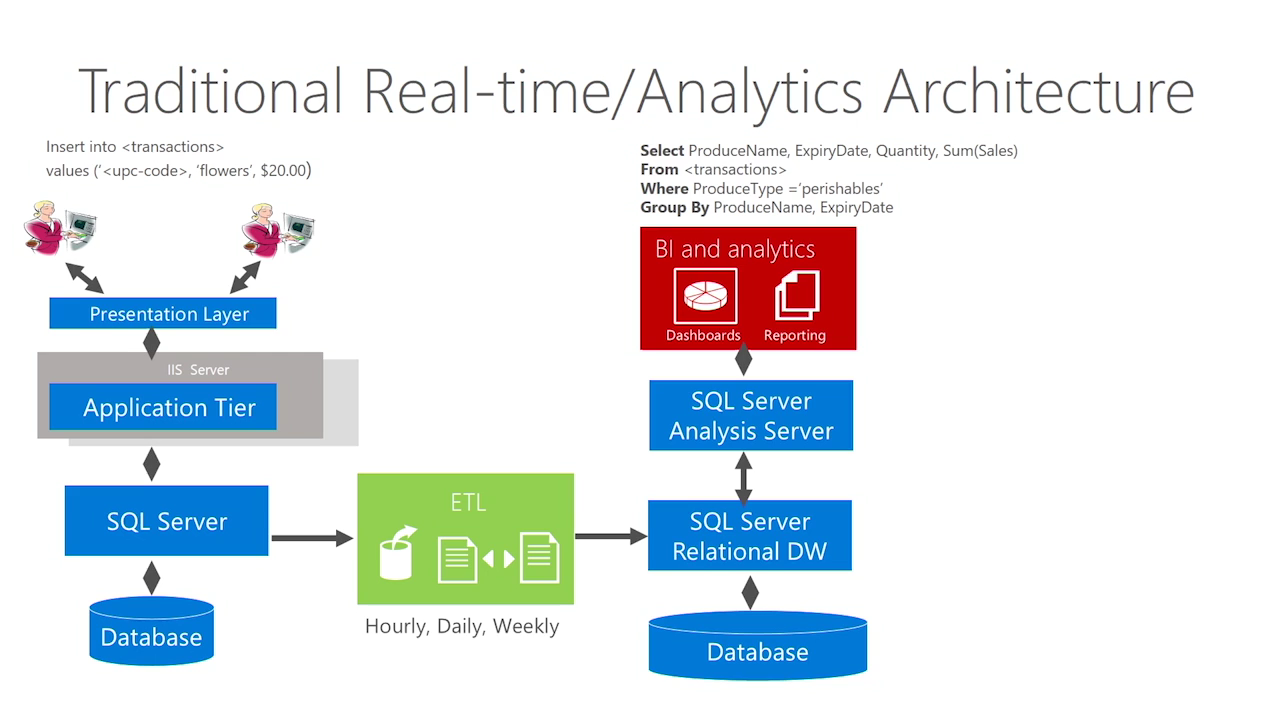
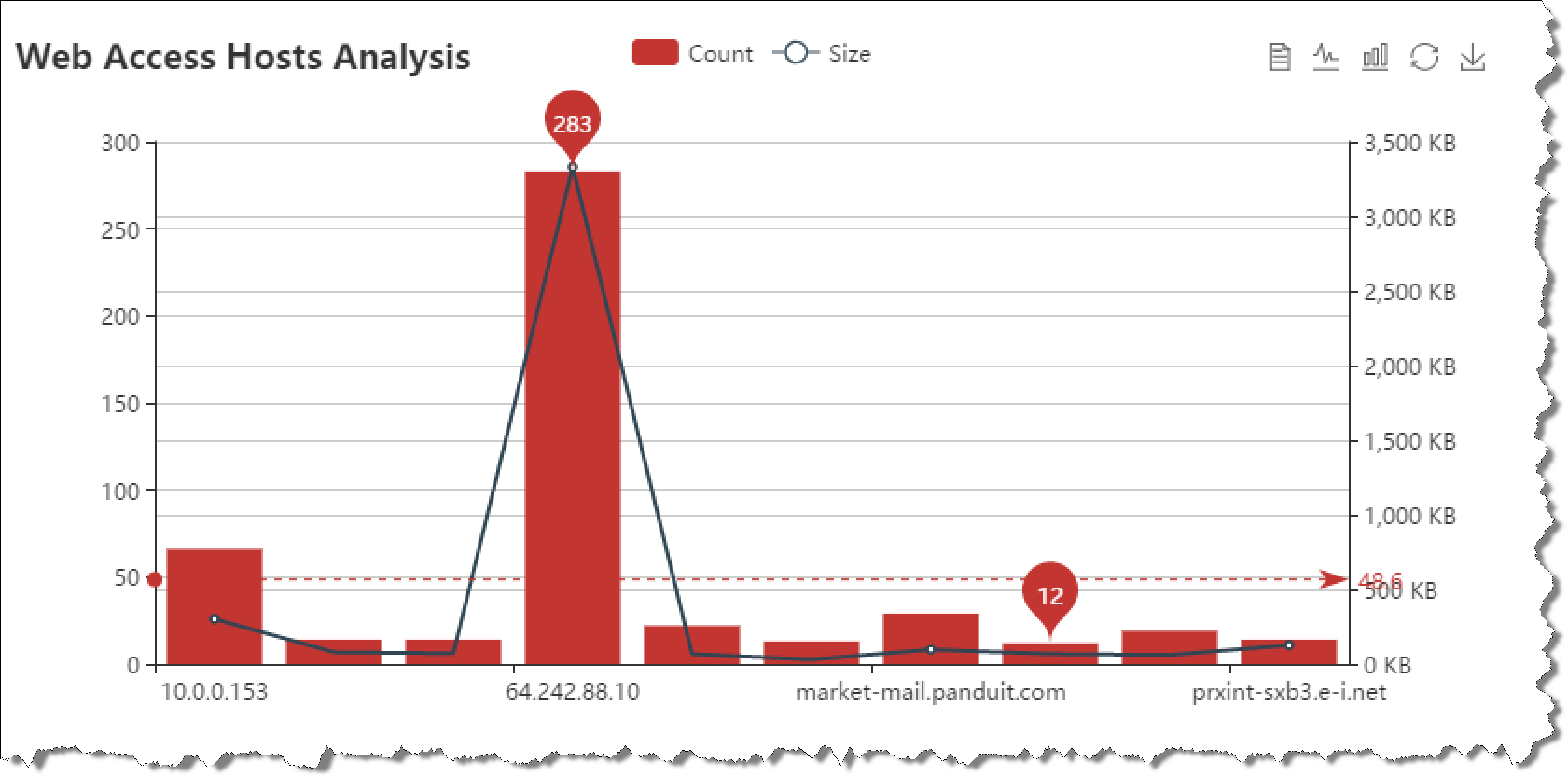
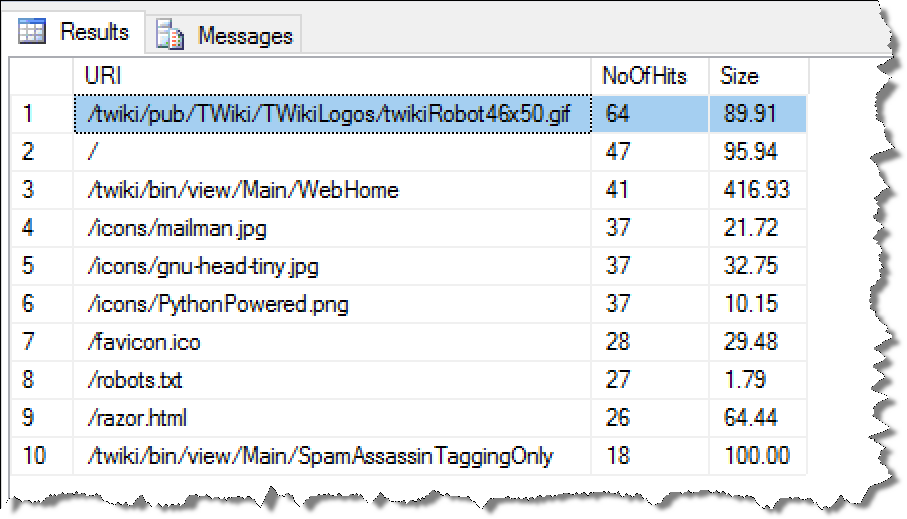
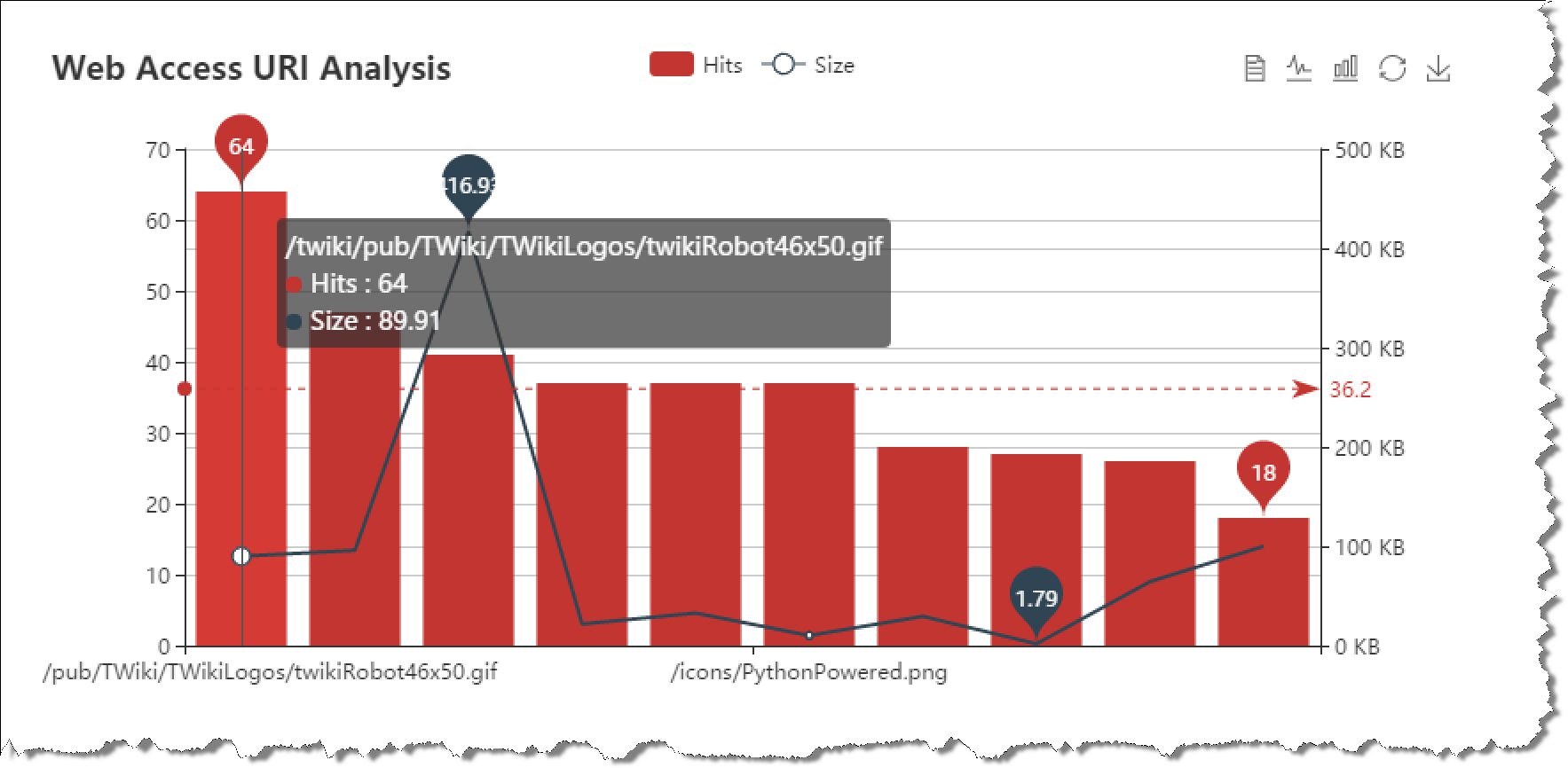
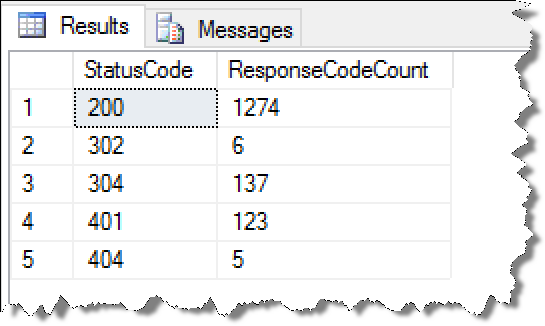
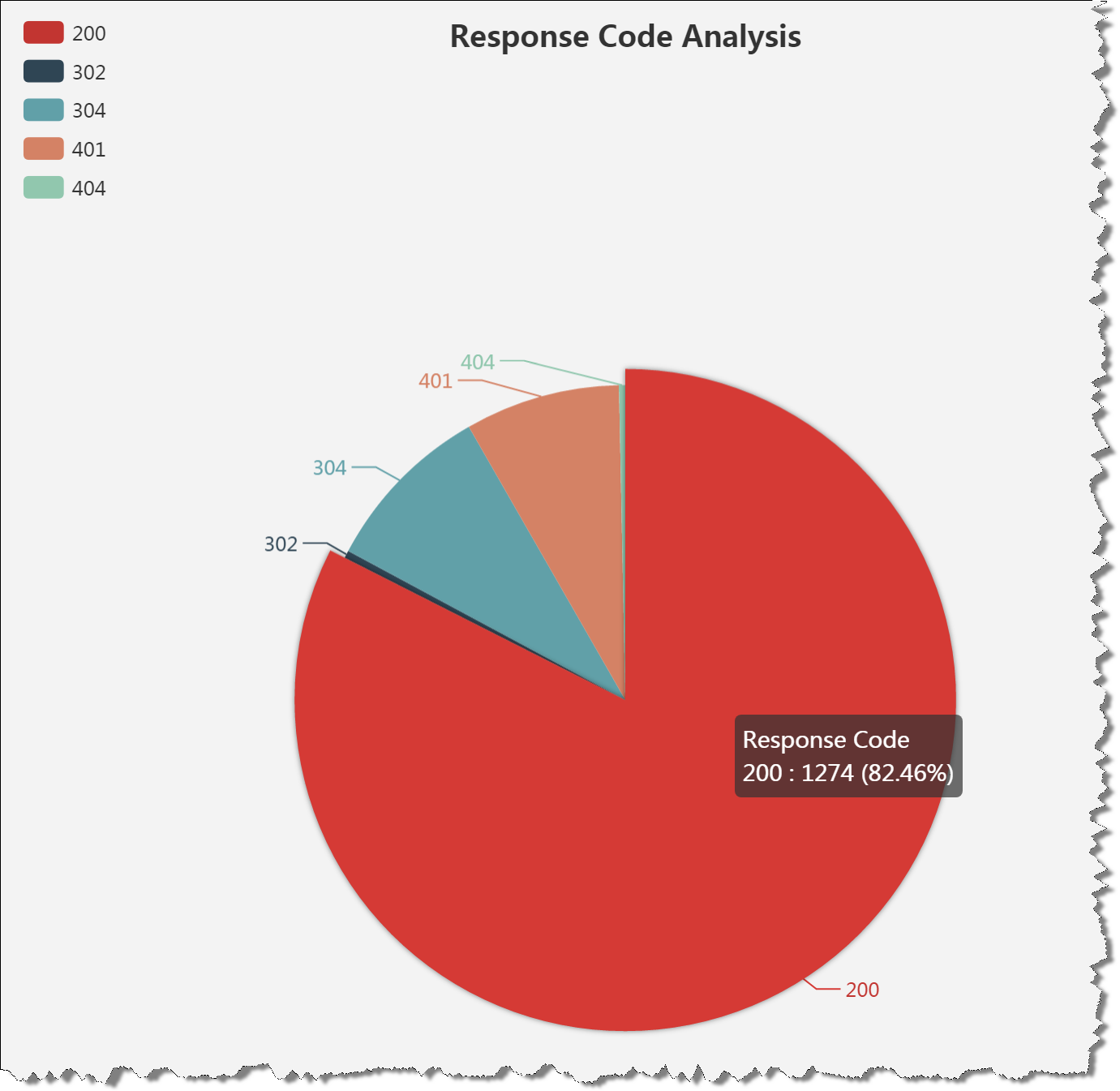
OLAP profiling 分析 (OLAP哪些过程最耗资源)
OLAP单个查询就会涉及大量数据的处理,与OLTP有非常鲜明的差别,那么数据库在OLAP场景会有哪些明显的瓶颈呢?
1. unpack row(tuple) 带来的开销
在PostgreSQL中,数据以行存储,变长类型可能存储在TOAST中,由于它是变长的,当访问第N列的数据时,也需要unpack前N-1列的内容数据(不过这块有优化空间,比如在行头记录每列的OFFSET,但是这样又引入另一个问题,增加了OFFSET必然会增加空间开销)。
另一种优化方法是业务层面的,比如将定长类型和变长类型拆分成两张或多张表,或者将不怎么访问的大字段拆开到其他表,通过JOIN关联它们。
不要小看这笔开销,这笔开销是O(N)的,所以数据量越大,开销越大,比如TPCH的Q6,40%是ROW格式化带来的开销。
2. 解释执行引入的开销
PostgreSQL的优化器通过构建树的方式来表述执行计划,所以执行器必须以递归的方式从树的最边缘节点一直往上执行。
解释执行的好处是弹性,容易改写,比如PG的customize scan ,GPU运算就用到了它。
通常解释执行比native code慢10倍,特别是在表达式非常多时。
你可以通过这种方式观察
postgres=# set debug_print_plan=true;
postgres=# set client_min_messages ='log';
3. 抽象层开销,PostgreSQL 的一个非常强悍的特性是允许用户自定义数据类型、操作符、UDF、索引方法等。为了支持这一特性,PostgreSQL将操作符与操作数剥离开来,通过调用FUNCTION的形式支持操作数的操作,譬如两个INT的加减运算,是通过调用FUNCTION来支持的。
a+b
可能就变成了
op1 func(a,b) {
c=a+b
return c
{
a op1 b
通过这种方式,支持了允许用户自定义数据类型、操作符。
通过函数调用的方式支持操作符,还引入了另一个问题,参数传递的memory copy操作。
所以,函数调用引入的overhead相比直接使用操作符(INT的加减乘除等)要大很多。
对于OLAP,不容小视。
4. PULL模型引入的overhead,PostgreSQL的executor是经典的Volcano-style query执行模型 - pull模型。操作数的值是操作符通过pull的模式来获取的。这样简化了执行器和操作符的设计和工程实现。
但是对性能有一定的影响,比如从一个node跳到另一个node时(比如seqscan或index scan节点,每获取一条tuple,跳到操作符函数),都需要保存或还原它们的上下文,对于OLAP,需要大批量的记录处理,这个开销放大就很厉害。
pull , push , pull on demand等模型,参考
https://www.infoq.com/news/2015/09/Push-Pull-Search
5. 多版本并发控制,这个基本上任何OLTP RDBMS都支持的特性,多版本主要用来解决高并发数据处理的问题。也成为了OLAP场景的一个包袱。
因为多版本并发控制,需要在每个TUPLE头部增加一些信息,比如infomask等(大概有20几个字节),通过infomask判断行的可见性。除了空间开销,同时判断行的可见性也引入了CPU的开销。
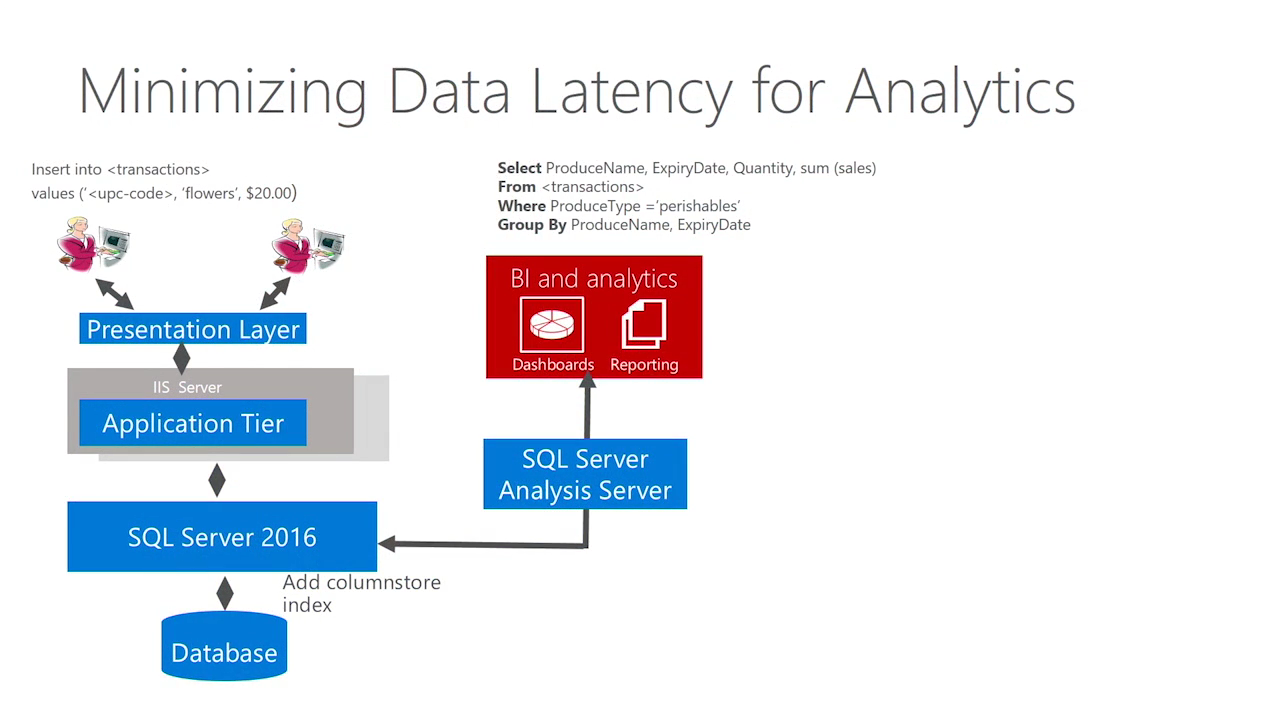
业界有哪些手段提升OLAP性能
1. 使用JIT(just in time)编译器,生成query的native code,消除tuple翻译瓶颈,即tuple deform的瓶颈,从而提高大批量数据处理的效率。
PostgreSQL-LLVM版本,就是使用的这种手段
《分析加速引擎黑科技 - LLVM、列存、多核并行、算子复用 大联姻 - 一起来开启PostgreSQL的百宝箱》
2. 重写优化器,将pull模型改写为push模型。
3. 面向OLAP,优化tuple的存储结构,提升deform tuple的效率。
4. 将query execution plan转换为二进制执行代码,消除执行树递归调用的方式引入的效率问题。
以上方法均需要重写PostgreSQL代码,甚至大改PostgreSQL架构。
那么有没有更友好的方法呢,不修改PostgreSQL内核,不动它的架构呢:
向量化计算。
向量化执行 与 列存储
传统的QUERY执行器在处理表达式时,是一行一行的处理模式。
比如在处理(x+y)这个表达式时,首先读取一条记录的X值,然后读取这条记录的Y值,然后执行+操作符。然后将结果返回给上层node。
然而,向量化执行器,一个操作符可以处理多个值,比如(x+y) ,x, y并不是scalar值,而是一批值的向量,向量化执行的结果也不是scalar值,而是向量。
向量化执行模型的会引入一定的解释和函数调用overhead,但是对于OLAP场景的大批量数据处理,这个overhead可以忽略。
既然向量化执行倾向于每次处理大批量的数据,那么在数据存放方面,也需要注意,比如OLAP经常需要对单列进行处理,使用列存储可以更好的和向量化执行模型结合起来。
OLAP场景,列存储有以下几个好处
减少每次计算时,需要读取或载入的数据大小(原来是以行来读取和载入),现在只需要载入计算需要用到的列。
压缩比更高,因为列的属性(类型)是固定的,数据按列存储时,在对应数据文件中所有值的类型是一样的,压缩比相比行存储高很多。
deform时,开销大大降低,不需要像行存储那样解释目标列以前的所有列(而且前面的列类型可能也不一致,引入更多的对应column 类型的deform的函数调用)。
可以使用CPU向量化指令(SIMD),处理批量数据
已经有一些数据库使用了列存储引擎,并且获得了很好的OLAP效率。比如Vertical, MonetDB。
既然向量化执行函数每次处理的是一类值的集合(向量),那么这个集合(向量)大小多大合适呢?
比如一张表有几亿条记录,我们需要计算sum((x+y)(x-y)),如果这几亿条记录作为一个(集合)向量,开始执行,会有什么后果呢?
因为CPU的CACHE大小是有限的,装不下这么大的数据,所以在算完一批数据的(x+y)后,再要算(x-y)时,前面的数据集合已经从CPU CACHE出去了,所以又要将数据LOAD一遍到CPU CACHE。
Table can be very large (OLAP queries are used to work with large data sets), so vector can also be very big and even doesn't fit in memory.
But even if it fits in memory, working with such larger vectors prevent efficient utilization of CPU caches (L1, L2,...).
Consider expression (x+y)(x-y).
Vector executor performs addition of two vectors : "x" and "y" and produces result vector "r1".
But when last element of vector "r" is produced, first elements of vector "r1" are already thrown from CPU cache, as well as first elements of "x" and "y" vectors.
So when we need to calculate (x-y) we once again have to load data for "x" and "y" from slow memory to fast cache.
Then we produce "r2" and perform multiplication of "r1" and "r2".
But here we also need first to load data for this vectors into the CPU cache.
将数据拆分成小的集合(chunk),分批运算是最好的,数据只需要进出CPU CACHE一遍。
也就是说,数据进入CPU CACHE后,算完所有的表达式,保存中间结果向量,然后再将下一批数据LOAD进CPU CACHE,继续运算。
CHUNK最好和CPU CACHE的大小匹配。
MonetDB x100上已经验证这种方法,性能提升了10倍。
https://www.monetdb.org/Home
So it is more efficient to split column into relatively small chunks (or tiles - there is no single notion for it accepted by everyone).
This chunk is a unit of processing by vectorized executor.
Size of such chunk is chosen to keep all operands of vector operations in cache even for complex expressions.
Typical size of chunk is from 100 to 1000 elements.
So in case of (x+y)(x-y) expression, we calculate it not for the whole column but only for 100 values (assume that size of the chunk is 100).
Splitting columns into chunks in successors of MonetDB x100 and HyPer allows to increase speed up to ten times.
PostgreSQL 向量化之路
前面讲了,向量化执行是打开OLAP性能之门的金钥匙之一,而要让向量化发挥效果,首先要使用列存储。
PostgreSQL 有两个列存储引擎,分别是cstore_fdw和imcs。
首先说说cstore_fdw,它是基于PostgreSQL的FDW接口实现的列存储插件,可以有效的减少tuple deform的开销,但是它使用标准的PostgreSQL raw-based 执行器,所以无法使用向量化处理。
https://github.com/citusdata/cstore_fdw
在CitusData公司内部,有一个基于cstore_fdw列存储引擎的项目,该项目通过PostgreSQL执行器的钩子接口,开发了一套基于cstore列存储的向量化执行器。数据聚合有4到6倍的性能提升,分组聚合有3倍的性能提升。
https://github.com/citusdata/postgres_vectorization_test
另一个项目是imcs, in-memory columnar store, 基于内存打造的一个列存引擎,操作时需要使用imcs项目提供的函数接口,不能使用标准的SQL,IMCS提供了向量计算(通过数据瓦片(tile)实现),以及并行执行的支持。
https://github.com/knizhnik/imcs
cstore和imcs插件虽然挺好的,但是数据毕竟不是使用的PostgreSQL内部存储,一个是FDW一个是内存。
如果我们想让数据存在PostgreSQL中,同时还要它支持向量计算,必须要改造PostgreSQL现有的行存储。
那么到底有没有更好的方法呢?其实是有的,新增瓦片式数据类型,瓦片本身支持向量计算。
前面讲到了向量计算的本质是一次计算多个值,减少函数调用,上下文切换,尽量的利用CPU的缓存以及向量化执行指令提高性能。
而为了达到这个目的,列存储是最适合的,为什么这么说,本质上列存储只是将数据做了物理的聚合,在使用时不需要像行存那样deform该列前面的其他列。
瓦片式存储类型,和列存储类似,可以达到类似的目的,你可以理解为单行存储了多行的数据。(比如你将某个字段的多行记录,按分组聚合为一个数组或JSONB,这只是个比喻,效果类似)
PostgreSQL VOPS插件就是这么做的,为每个数据类型,新增了一个对应的瓦片数据类型,比如real类型对应新增了一个vops_float4类型,它可以表述最多64个real值。
为什么是64呢,PostgreSQL VOPS给出了如下理由
为了有效的访问瓦片,size_of_tile * size_of_attribute * number_of_attributes这几个属性相乘不能超过PostgreSQL单个数据块的大小。典型的一张表假设有10个字段即attribute,PostgreSQL默认的数据块为8KB。
我们需要用掩码来标记空值,64 BIT的整型来表示这个掩码效率是最高的,所以这也是一个瓦片最多存储64个VALUE的理由之一。
最后一点是和CPU CACHE有关的,通常CPU CACHE可以用来一次处理100到1000(经验值)个VALUE(向量化处理),所以瓦片的大小也要考虑这一点,一个瓦片最好能刚好吧CPU CACHE用尽。将来如果CPU CACHE做大了,我们可以再调整瓦片的大小。
PostgreSQL VOPS权衡了CSTORE和IMCS的弊端,在不改造PostgreSQL存储引擎,不改执行器,不使用钩子的情况下,利用瓦片式数据类型,有效的利用CPU CACHE以及向量化执行指令,将OLAP场景的性能提升了10倍。
新增的瓦片式类型,对应的还新增了对应的向量化执行操作符,所以使用VOPS和正常的使用SQL语法是一样的。
使用VOPS,总共分三步。
1. 创建基础表的VOPS表(使用对应的瓦片类型)。
2. 调用VOPS提供的转换函数,将基础表的数据转移到VOPS表(即转换、规整为瓦片存储的过程)。
3. 使用正常的SQL,访问VOPS表即可,但是需要注意,使用VOPS提供的操作符哦。
PostgreSQL VOPS新增 瓦片类型
VOPS 目前支持的数据类型如下
| SQL type | C type | VOPS tile type |
|---|
| bool | bool | vops_bool |
| “char”, char or char(1) | char | vops_char |
| int2 | int16 | vops_int2 |
| int4 | int32 | vops_int4 |
| int8 | int64 | vops_int8 |
| float4 | float4 | vops_float4 |
| float8 | float8 | vops_float8 |
| date | DateADT | vops_date |
| timestamp | Timestamp | vops_timestamp |
VOPS 目前不支持string,如果你使用了STRING字段,并且需要用来统计的话,建议可以使用INT8将其字典化,然后就可以利用VOPS特性了。
PostgreSQL VOPS新增 瓦片类型操作符
前面说了,正规的VOPS使用方法,总共分三步,这第三步涉及的就是操作符,因为是瓦片类型,VOPS重写了对应的操作符来支持向量计算。
1. VOPS数值瓦片类型,支持的+ - / *保持原样不变。
2. 比较操作符= <> > >= < <=保持原样不变。
这些操作符支持瓦片类型之间的运算,支持瓦片类型与scalar(原有标量类型)的常量之间的运算。
3. 逻辑操作符 and, or, not 是SQL PARSER部分,没有开放重写,所以VOPS定义了3个操作符来对应他们的功能。
& | !,相信一看就明白了吧。
例如
x=1 or x=2
改写成
(x=1) | (x=2)
注意把他们当成逻辑操作符时,必须用括号,因为m&,|,! 几个原始操作符的优先级很高, 会误认为是原始操作符,报语法错误
注意逻辑操作符,返回的数据类型为vops_boolean,并不是boolean。
4. x BETWEEN a AND b 等同于 x >=a AND x<=b,但是由于BETWEEN AND无法重写,所以VOPS使用betwixt函数来代替这个语法。
x BETWEEN a AND b
改写成
betwixt(x, a , b)
betwixt函数,返回的数据类型为vops_boolean,也不是boolean。
5. 因为向量计算中,逻辑操作返回的是vops_boolean类型而不是boolean类型,所以PostgreSQL对vops_boolean类型进行断言,VOPS为了解决这个场景,使用了filter函数来处理断言。
例如
where (x=1) | (x=2)
改写成
where filter( (x=1) | (x=2) )
所有的断言,都需要使用filter()函数
filter()函数处理的是vops_boolean,返回的是boolean,但是filter()会对传入参数的内容设置filter_mask,用于后面的向量处理选择符合条件的数据。filter()任何情况下都返回boolean:true(让PostgreSQL执行器继续下去),这不影响整个向量计算的过程和结果。
6. 除了函数调用,所有的向量化计算操作符,在传入字符串常量时,必须显示转换。
例如
select sum(price) from trades where filter(day >= '2017-01-01'::date);
不能写成
select sum(price) from trades where filter(day >= '2017-01-01');
而函数内,可以不使用显示转换
select sum(price) from trades where filter(betwixt(day, '2017-01-01', '2017-02-01'));
7. 对于char, int2, int4类型,VOPS提供了一个连接符||,用于如下合并
(char || char) -> int2, (int2 || int2) -> int4, (int4 || int4) -> int8.
这么做,目的是用于多个字段的GROUP BY,提高GROUP BY效率。
8. VOPS提供的操作符,整合如下
| Operator | Description |
|---|
| + | Addition |
| - | Binary subtraction or unary negation |
* | Multiplication |
| / | Division |
| = | Equals |
| <> | Not equals |
| < | Less than |
| <= | Less than or Equals |
| > | Greater than |
| >= | Greater than or equals |
| & | Boolean AND |
| | Boolean OR |
| ! | Boolean NOT |
| betwixt(x,low,high) | Analog of BETWEEN |
| is_null(x) | Analog of IS NULL |
| is_not_null(x) | Analog of IS NOT NULL |
| ifnull(x,subst) | Analog of COALESCE |
PostgreSQL VOPS 聚合函数
VOPS目前已经支持的聚合向量化计算,包括一些常用的聚合函数,如下
count, min, max, sum, avg
聚合分为两种,一种是非分组聚合,一种是分组聚合。
1. VOPS处理非分组聚合,和PostgreSQL原有用法一样,例如:
select sum(l_extendedpricel_discount) as revenue
from vops_lineitem
where filter(betwixt(l_shipdate, '1996-01-01', '1997-01-01')
& betwixt(l_discount, 0.08, 0.1)
& (l_quantity < 24));
2. VOPS处理带有group by的分组聚合稍微复杂一些,需要用到map和reduce函数。
map函数实现聚合操作,并且返回一个HASH TABLE(包含了所有GROUP的聚合后的信息),reduce函数则将hash table的数据一条条解析并返回。
所以可以看出MAP函数是运算,reduce函数是返回结果。
map函数语法
map(group_by_expression, aggregate_list, expr {, expr })
可见map是一个vardic参数函数,所以expr的数据类型必须一致。
reduce函数语法
reduce(map(...))
例子
select
sum(l_quantity),
sum(l_extendedprice),
sum(l_extendedprice(1-l_discount)),
sum(l_extendedprice(1-l_discount)(1+l_tax)),
avg(l_quantity),
avg(l_extendedprice),
avg(l_discount)
from vops_lineitem
where l_shipdate <= '1998-12-01'::date
group by l_returnflag, l_linestatus;
改写为
select reduce(map(l_returnflag||l_linestatus, 'sum,sum,sum,sum,avg,avg,avg',
l_quantity,
l_extendedprice,
l_extendedprice(1-l_discount),
l_extendedprice(1-l_discount)(1+l_tax),
l_quantity,
l_extendedprice,
l_discount))
from vops_lineitem
where filter(l_shipdate <= '1998-12-01'::date);
VOPS限制:
1. 目前VOPS只支持INT类型的聚合操作(int2, int4, int8)。
2. 由于map函数是vardic参数函数,所以末尾的所有expr类型必须一致(请参考PostgreSQL vardic函数的编写),所有的expr类型必须一致,即 sum(expr1),avg(expr2),…,这些expr类型必须一致。
map(group_by_expression, aggregate_list, expr {, expr })
expr类型必须一致
map, reduce 函数详解 :
1. map函数的第二个参数是聚合函数,用逗号隔开,count(*)不需要写明,因为reduce函数默认就会返回每个分组的count(*)。
count(字段)则需要写明。
例如
map(c1||c2, 'count,max,avg,max', c3, c4, c5, c6)
表示
count(*),
count(c3),
max(c4).
avg(c5),
max(c6)
group by
c1, c2;
2. reduce函数,返回的是vops_aggregate类型的多条记录集合,即returns setof vops_aggregate;
vops_aggregate类型是复合类型,包括三个部分,
分组字段的值,例如group by a,那么它表示每个A字段分组的值。
分组的记录数,例如group by a,那么它表示每个A字符分组有多少条记录。
聚合结果数组(因为可能有多个聚合表达式,所以返回的是数组),因为PG的数组必须是单一类型,所以VOPS的聚合结果必须返回统一类型,目前vops定义的所有vops聚合函数返回的都是float类型。
定义如下
create type vops_aggregates as(group_by int8, count int8, aggs float8[]);
create function reduce(bigint) returns setof vops_aggregates;
VOPS分组聚合最佳实践,
将需要执行聚合操作的表,按分组字段分区,即选择分组字段,作为分区字段。(并非分区表的意思哦,而是对分区字段使用scalar类型,即非vops类型,后面将populate会讲)
那么在VOPS执行分组聚合时,实际上PostgreSQL的优化器会让其在各自的分区执行表级聚合,而非分组聚合。
所以分组聚合就变成了非分组聚合操作,也就不需要使用map, reduce的写法了。
如下
select
l_returnflag,
l_linestatus,
sum(l_quantity) as sum_qty,
sum(l_extendedprice) as sum_base_price,
sum(l_extendedprice(1-l_discount)) as sum_disc_price,
sum(l_extendedprice(1-l_discount)(1+l_tax)) as sum_charge,
avg(l_quantity) as avg_qty,
avg(l_extendedprice) as avg_price,
avg(l_discount) as avg_disc,
countall(*) as count_order
from
vops_lineitem_projection
where
filter(l_shipdate <= '1998-12-01'::date)
group by
l_returnflag,
l_linestatus
order by
l_returnflag,
l_linestatus;
| 以上SQL例子,分组字段l_returnflag, l_linestatus字段为”char”类型,使用连接符 | | 可以将其变成vops_int2类型。 |
其他字段是vops_float4类型。
以上SQL执行速度比reduce(map(…))快很多,问题是我们必须实现规划好分区,分区键与GROUP BY分组键一致。
VOPS 瓦片索引
通常情况下,OLAP场景并不需要使用索引,因为数据分区,列存储,以及向量计算相比索引可以更为有效的解决OLAP的性能问题。
但是索引作为数据过滤,也不失为一种好的选择。
但是VOPS已经将数据改为瓦片式存储(在一个瓦片中存储了原有的多条记录的某列的值),那么如何才能对瓦片数据创建索引呢?
我们当然不能将瓦片先解开,再来创建索引,这样无法取得好的效果,但是我们可以结合瓦片的特点,创建BRIN索引。
BRIN索引用于记录某些连续的数据块中的元数据,最大值,最小值,平均值,多少空值等。非常适合瓦片数据,因为瓦片本身就是个聚集。
另外BRIN更适合于存储顺序,与实际的逻辑值 线性相关的数据,比如递增字段。流式数据的递增字段,实际字段,序列字段等。。
关于BRIN索引的原理和应用场景,可以参考
《PostgreSQL 聚集存储 与 BRIN索引 - 高并发行为、轨迹类大吞吐数据查询场景解说》
《PostgreSQL 9.5 new feature - lets BRIN be used with R-Tree-like indexing strategies For “inclusion” opclasses》
《PostgreSQL 9.5 new feature - BRIN (block range index) index》
为了让PostgreSQL支持瓦片,我们需要将每个瓦片内的最大值和最小值取出,使用函数的方式,返回scalar类型,然后对scalar类型创建BRIN索引。
VOPS提供4个函数,可以将瓦片内的最大值,最小值取出
当VOPS表按某个字段排序存储时(即物理存储于逻辑值 完全线性相关),使用first, last函数,取出该字段的 最小值和最大值。
当VOPS表没有按某个字段排序存储时,则需要使用high和low,取出该字段的 最大值和最小值。
注意high, low需要额外的排序操作,效率略低。
first和last不需要排序,因为瓦片内的内容已经排序,所以效率很高。
例子
create index low_boundary on trades using brin(first(day)); -- trades table is ordered by day
create index high_boundary on trades using brin(last(day)); -- trades table is ordered by day
first, last, high, low返回的是PostgreSQL原生boolean,而不是vops_boolean,所以不需要加filter,可以直接写在where表达式中。
那么下面这个QUERY可以用到以上索引
select sum(price) from trades where first(day) >= '2015-01-01' and last(day) <= '2016-01-01'
and filter(betwixt(day, '2015-01-01', '2016-01-01'));
普通表转换为 VOPS瓦片表
前面讲了,VOPS的核心是向量计算,而向量计算依赖数据的BATCH存储,(例如列存储),vops在不改动现有PostgreSQL代码的情况下,要支持向量计算,使用的是新增瓦片数据类型(一个瓦片存储原同一字段的多条记录的值)的方法。
所以,首先,必须要将表转换为VOPS的瓦片存储表。
vops提供了populate函数来完成这个工作。
过程如下
1. 创建原始表的VOPS对应表,数据类型使用vops提供的瓦片数据类型对应。
这个动作和vertica数据库的projection工作类似(它只将常用字段转换)。
例如,原始表如下
create table lineitem(
l_orderkey integer,
l_partkey integer,
l_suppkey integer,
l_linenumber integer,
l_quantity real,
l_extendedprice real,
l_discount real,
l_tax real,
l_returnflag char,
l_linestatus char,
l_shipdate date,
l_commitdate date,
l_receiptdate date,
l_shipinstruct char(25),
l_shipmode char(10),
l_comment char(44));
VOPS projection of this table如下 , 我们只选择了需要用到的字段,进行转换,所以我们也称为projection吧:
create table vops_lineitem(
l_shipdate vops_date not null,
l_quantity vops_float4 not null,
l_extendedprice vops_float4 not null,
l_discount vops_float4 not null,
l_tax vops_float4 not null,
l_returnflag vops_char not null,
l_linestatus vops_char not null
);
我们可以把原始表称为写优化表(write optimized storage (WOS)),它不需要任何索引,写入速度可以做到非常非常快。
而VOPS表,我们称为读优化表(read-optimized storage (ROS)),对OLAP的查询请求进行优化,速度有10倍以上的提升。
2. 使用VOPS提供的populate函数,完成projection数据转换的动作
create function populate(destination regclass,
source regclass,
predicate cstring default null,
sort cstring default null);
前两个参数是强制参数,第一个表示VOPS表的regclass,第二个是原始表的regclass,
predicate参数用于合并数据,将最近接收的数据合并到已有数据的VOPS表。
sort是告诉populate,按什么字段排序,前面讲索引时有讲到为什么需要排序,就是要线性相关性,好创建first, last的brin索引。
当然,还有一个用途,就是QUERY返回结果时按照sort指定的字段order by,可以不需要显示的sort。
例子
select populate(destination := 'vops_lineitem'::regclass, source := 'lineitem'::regclass);
vops表全表扫描的速度比普通表要快,一方面是瓦片式存储,另一方面,它可以使用向量计算,提高了filter和聚合操作的速度。
分组聚合需要reduce(map(…)),非分组聚合不需要使用reduce(map(…)),也没有map,reduce的诸多限制(请参考前面章节)。
如果我们需要分组聚合,并且想使用普通的QUERY写法(而非map,reduce),那么可以将分组字段,作为分区字段。
在选择分区字段时,我们的建议是,分区字段不要选择唯一字段(重复值更好,因为对它排序后,它可以单一值存储,而同时更加有利于其他字段的瓦片化),你总不会拿唯一字段取做group by 吧。
另一方面,我们建议对分区字段排序存储,这样可以帮助降低存储空间,查询效率也更高。(虽然它scalar类型,非瓦片类型)
例子
create table vops_lineitem_projection(
l_shipdate vops_date not null,
l_quantity vops_float4 not null,
l_extendedprice vops_float4 not null,
l_discount vops_float4 not null,
l_tax vops_float4 not null,
l_returnflag "char" not null,
l_linestatus "char" not null
);
分区字段选择了 l_returnflag and l_linestatus ,其他字段则为瓦片字段类型.
projection操作如下
select populate(destination := 'vops_lineitem_projection'::regclass, source := 'lineitem_projection'::regclass, sort := 'l_returnflag,l_linestatus');
现在,你可以对分区字段创建普通索引,使用普通的group by, order by,标准达到prediction( where …),不需要使用filter。
查询瓦片表,如何返回正常记录
我们在查询projection后的vops表时,返回的都是瓦片记录,那么如何转换为正常记录呢?
类似聚合后的数据,如何进行行列变化,变成多行返回。
使用unnest函数即可(unnest函数也常被用于数组,JSON,HSTORE等类型的行列变换),如下
postgres=# select unnest(l.) from vops_lineitem l where filter(l_shipdate <= '1998-12-01'::date) limit 3;
unnest
---------------------------------------
(1996-03-13,17,33078.9,0.04,0.02,N,O)
(1996-04-12,36,38306.2,0.09,0.06,N,O)
(1996-01-29,8,15479.7,0.1,0.02,N,O)
(3 rows)
好消息,标准SQL支持 - 自动化转换与parser analyze钩子
前面看了一大堆VOPS特定的类型,操作符,函数等,好像VOPS用起来要改写一堆的SQL对吧。
好消息来了,VOPS提供了parser analyze hook,另外PostgreSQL本身提供了自定义类型、自定义操作符、自定义类型隐式转换的功能。
User defined types
User defined operator
User defined implicit type casts
Post parse analyze hook which performs query transformation
HOOK与之结合,我们就可以让VOPS支持标准SQL,而不需要考虑前面的那些SQL写法了,让标准SQL支持向量计算。
(PS: VOPS的projection (population)过程是省不掉的,这是开发或者DBA的职责。)
具体如何做呢?
1. VOPS 已经定义了瓦片类型,以及瓦片对象的标准SQL操作符,我们不需要做什么。
2. VOPS 定义了vops_bool瓦片类型的隐式转换,vops_bool转换为boolean(scalar)类型。
3. 开发人员不需要使用filter(vops_boolean)了。
4. 最后,VOPS的parse analyze hook,帮助你将标准的SQL,改写为VOPS的执行SQL(就是我们前面学的那一堆),解放了程序猿的大脑。
转换前后对比,左边为程序猿写的,右边是parse analyze hook转换后的
| Original expression | Result of transformation |
|---|
| NOT filter(o1) | filter(vops_bool_not(o1)) |
| filter(o1) AND filter(o2) | filter(vops_bool_and(o1, o2)) |
| filter(o1) OR filter(o2) | filter(vops_bool_or(o1, o2)) |
5. 我们也不需要使用betwixt函数来代替between and了,只需要写标准的between and即可。(但是依旧建议使用betwixt(c,v1,v2),单个函数比较两个值,效率更高)
| 6. (x>=1) | (x<=0),这个括号也不需要了。 |
7. 如果查询包含了向量聚合操作,count(*)会自动转换为countall(*)。而不会报错。
8. 当我们在瓦片类型的操作符后吗传入STRING时,目前还需要使用显示转换。
例如
l_shipdate如果是瓦片类型,那么以下必须加显示转换
l_shipdate <= '1998-12-01'加显示转换
l_shipdate <= '1998-12-01'::date
因为有两个一样的重载操作符
vops_date <= vops_date
vops_date <= date
post parse analyze hook使用注意 - 首次使用,需通过vops_initialize载入或者配置shared_preload_libraries
由于VOPS使用的是post parse analyze hook,并且通过 _PG_init 函数加载。
如果你没有将vops.so配置进shared_preload_libraries,那么 _PG_init 函数是在会话使用到它是才会被载入,然而他的载入是晚于parse analyze的,因为一次调用QUERY,parse analyze就结束了。所以这种情况QUERY可能得到错误的结果。
因此你要么将vops.so配置进shared_preload_libraries,让数据库启动时就加载钩子。
要么,你可以在执行QUERY前,先执行一下vops_initialize()函数,人为的载入钩子。
VOPS 使用例子
既然VOPS 向量计算是为OLAP而生的,所以自然,我需要测试的是OLAP领域的TPC-H。
tpc-h包含了21个QUERY,接下来的例子测试的是Q1和Q6,没有使用JOIN,前面说了VOPS目前还不支持JOIN。
代码如下
-- Standard way of creating extension
create extension vops;
-- Original TPC-H table
create table lineitem(
l_orderkey integer,
l_partkey integer,
l_suppkey integer,
l_linenumber integer,
l_quantity real,
l_extendedprice real,
l_discount real,
l_tax real,
l_returnflag char,
l_linestatus char,
l_shipdate date,
l_commitdate date,
l_receiptdate date,
l_shipinstruct char(25),
l_shipmode char(10),
l_comment char(44),
l_dummy char(1)); -- this table is needed because of terminator after last column in generated data
-- Import data to it
copy lineitem from '/mnt/data/lineitem.tbl' delimiter '|' csv;
-- Create VOPS projection
create table vops_lineitem(
l_shipdate vops_date not null,
l_quantity vops_float4 not null,
l_extendedprice vops_float4 not null,
l_discount vops_float4 not null,
l_tax vops_float4 not null,
l_returnflag vops_char not null,
l_linestatus vops_char not null
);
-- Copy data to the projection table
select populate(destination := 'vops_lineitem'::regclass, source := 'lineitem'::regclass);
-- For honest comparison creates the same projection without VOPS types
create table lineitem_projection as (select l_shipdate,l_quantity,l_extendedprice,l_discount,l_tax,l_returnflag::"char",l_linestatus::"char" from lineitem);
-- Now create mixed projection with partitioning keys:
create table vops_lineitem_projection(
l_shipdate vops_date not null,
l_quantity vops_float4 not null,
l_extendedprice vops_float4 not null,
l_discount vops_float4 not null,
l_tax vops_float4 not null,
l_returnflag "char" not null,
l_linestatus "char" not null
);
-- And populate it with data sorted by partitioning key:
select populate(destination := 'vops_lineitem_projection'::regclass, source := 'lineitem_projection'::regclass, sort := 'l_returnflag,l_linestatus');
-- Let's measure time
\timing
-- Original Q6 query performing filtering with calculation of grand aggregate
select
sum(l_extendedpricel_discount) as revenue
from
lineitem
where
l_shipdate between '1996-01-01' and '1997-01-01'
and l_discount between 0.08 and 0.1
and l_quantity < 24;
-- VOPS version of Q6 using VOPS specific operators
select sum(l_extendedpricel_discount) as revenue
from vops_lineitem
where filter(betwixt(l_shipdate, '1996-01-01', '1997-01-01')
& betwixt(l_discount, 0.08, 0.1)
& (l_quantity < 24));
-- Yet another vectorized version of Q6, but now in stadnard SQL:
select sum(l_extendedpricel_discount) as revenue
from vops_lineitem
where l_shipdate between '1996-01-01'::date AND '1997-01-01'::date
and l_discount between 0.08 and 0.1
and l_quantity < 24;
-- Original version of Q1: filter + group by + aggregation
select
l_returnflag,
l_linestatus,
sum(l_quantity) as sum_qty,
sum(l_extendedprice) as sum_base_price,
sum(l_extendedprice(1-l_discount)) as sum_disc_price,
sum(l_extendedprice(1-l_discount)(1+l_tax)) as sum_charge,
avg(l_quantity) as avg_qty,
avg(l_extendedprice) as avg_price,
avg(l_discount) as avg_disc,
count() as count_order
from
lineitem
where
l_shipdate <= '1998-12-01'
group by
l_returnflag,
l_linestatus
order by
l_returnflag,
l_linestatus;
-- VOPS version of Q1, sorry - no final sorting
select reduce(map(l_returnflag||l_linestatus, 'sum,sum,sum,sum,avg,avg,avg',
l_quantity,
l_extendedprice,
l_extendedprice(1-l_discount),
l_extendedprice(1-l_discount)(1+l_tax),
l_quantity,
l_extendedprice,
l_discount)) from vops_lineitem where filter(l_shipdate <= '1998-12-01'::date);
-- Mixed mode: let's Postgres does group by and calculates VOPS aggregates for each group
select
l_returnflag,
l_linestatus,
sum(l_quantity) as sum_qty,
sum(l_extendedprice) as sum_base_price,
sum(l_extendedprice(1-l_discount)) as sum_disc_price,
sum(l_extendedprice(1-l_discount)(1+l_tax)) as sum_charge,
avg(l_quantity) as avg_qty,
avg(l_extendedprice) as avg_price,
avg(l_discount) as avg_disc,
count() as count_order
from
vops_lineitem_projection
where
l_shipdate <= '1998-12-01'::date
group by
l_returnflag,
l_linestatus
order by
l_returnflag,
l_linestatus;
测试性能对比
测试环境和配置如下,数据可以放入整个内存,所以不用考虑IO影响,同时测试了单核与多核并行模式(因为PostgreSQL支持一个QUERY使用多个CPU核)。
All measurements were performed at desktop with 16Gb of RAM and quad-core i7-4770 CPU @ 3.40GHz processor with enabled hyper-threading.
Data set for benchmark was generated by dbgen utility included in TPC-H benchmark.
Scale factor is 100 which corresponds to about 8Gb database.
It can completely fit in memory, so we are measuring best query execution time for warm data.
Postgres was configured with shared buffer size equal to 8Gb.
For each query we measured time of sequential and parallel execution with 8 parallel workers.
性能对比如下
| Query | Sequential execution (msec) | Parallel execution (msec) |
|---|
| Original Q1 for lineitem | 38028 | 10997 |
| Original Q1 for lineitem_projection | 33872 | 9656 |
| Vectorized Q1 for vops_lineitem | 3372 | 951 |
| Mixed Q1 for vops_lineitem_projection | 1490 | 396 |
| Original Q6 for lineitem | 16796 | 4110 |
| Original Q6 for lineitem_projection | 4279 | 1171 |
| Vectorized Q6 for vops_lineitem | 875 | 284 |
结论
从测试结果来看,使用VOPS向量计算后,性能有了10倍的提升,相比LLVM的4倍和3倍,取得了更好的效果。
同时,使用瓦片式的方法,不需要修改数据库内核,可以以插件的形式装载,适合更多的用户使用。
As you can see in performance results, VOPS can provide more than 10 times improvement of query speed.
And this result is achieved without changing something in query planner and executor.
It is better than any of existed attempt to speed up execution of OLAP queries using JIT (4 times for Q1, 3 times for Q6):
Speeding up query execution in PostgreSQL using LLVM JIT compiler.
Definitely VOPS extension is just a prototype which main role is to demonstrate potential of vectorized executor.
But I hope that it also can be useful in practice to speedup execution of OLAP aggregation queries for existed databases.
And in future we should think about the best approach of integrating vectorized executor in Postgres core.
ALL sources of VOPS project can be obtained from this GIT repository.
Please send any feedbacks, complaints, bug reports, change requests to Konstantin Knizhnik.
小结
PostgreSQL数据库近几年的发展让很多商业数据库都汗颜,在OLTP领域担当了开源关系数据库领头雁的职责,在OLAP领域又在不断地发力。
从多核并行、GPU加速、FPGA加速到JIT,再到向量计算。在计算能力方面不断的提高。
同时,PostgreSQL设置在分布式方面也已经小有成就,例如已支持聚合下推、算子下推、WHERE子句下推,SORT\JOIN下推等等一系列的postgres_fdw的完善。(还有基于PG的分布式数据库greenplum, redshift, pgxc, pgxz等等就不多说了)
PostgreSQL势必要在OLTP和OLAP领域大放异彩。
参考
https://github.com/citusdata/postgres_vectorization_test
https://github.com/citusdata/cstore_fdw
https://github.com/knizhnik/imcs
https://www.monetdb.org/Home
https://github.com/postgrespro/vops