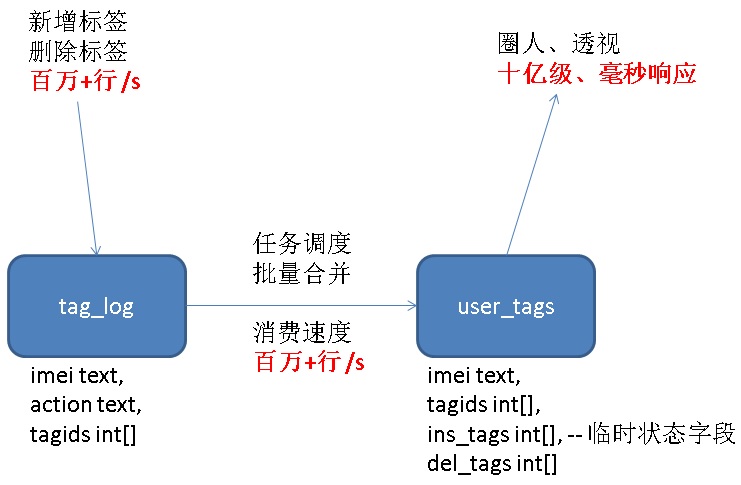
前言
关系型数据库的事务机制因其有原子性,一致性等优秀特性深受开发者喜爱,类似的思想已经被应用到很多其他系统上,例如文件系统等。本文主要介绍InnoDB事务子系统,主要包括,事务的启动,事务的提交,事务的回滚,多版本控制,垃圾清理,回滚段以及相应的参数和监控方法。代码主要基于RDS 5.6,部分特性已经开源到AliSQL。事务系统是InnoDB最核心的中控系统,涉及的代码比较多,主要集中在trx目录,read目录以及row目录中的一部分,包括头文件和IC文件,一共有两万两千多行代码。
基础知识
事务ACID:原子性,指的是整个事务要么全部成功,要么全部失败,对InnoDB来说,只要client收到server发送过来的commit成功报文,那么这个事务一定是成功的。如果收到的是rollback的成功报文,那么整个事务的所有操作一定都要被回滚掉,就好像什么都没执行过一样。另外,如果连接中途断开或者server crash事务也要保证会滚掉。InnoDB通过undolog保证rollback的时候能找到之前的数据。一致性,指的是在任何时刻,包括数据库正常提供服务的时候,数据库从异常中恢复过来的时候,数据都是一致的,保证不会读到中间状态的数据。在InnoDB中,主要通过crash recovery和double write buffer的机制保证数据的一致性。隔离性,指的是多个事务可以同时对数据进行修改,但是相互不影响。InnoDB中,依据不同的业务场景,有四种隔离级别可以选择。默认是RR隔离级别,因为相比于RC,InnoDB的RR性能更加好。持久性,值的是事务commit的数据在任何情况下都不能丢。在内部实现中,InnoDB通过redolog保证已经commit的数据一定不会丢失。
多版本控制:指的是一种提高并发的技术。最早的数据库系统,只有读读之间可以并发,读写,写读,写写都要阻塞。引入多版本之后,只有写写之间相互阻塞,其他三种操作都可以并行,这样大幅度提高了InnoDB的并发度。在内部实现中,与Postgres在数据行上实现多版本不同,InnoDB是在undolog中实现的,通过undolog可以找回数据的历史版本。找回的数据历史版本可以提供给用户读(按照隔离级别的定义,有些读请求只能看到比较老的数据版本),也可以在回滚的时候覆盖数据页上的数据。在InnoDB内部中,会记录一个全局的活跃读写事务数组,其主要用来判断事务的可见性。
垃圾清理:对于用户删除的数据,InnoDB并不是立刻删除,而是标记一下,后台线程批量的真正删除。类似的还有InnoDB的二级索引的更新操作,不是直接对索引进行更新,而是标记一下,然后产生一条新的。这个线程就是后台的Purge线程。此外,过期的undolog也需要回收,这里说的过期,指的是undo不需要被用来构建之前的版本,也不需要用来回滚事务。
回滚段:可以理解为数据页的修改链,链表最前面的是最老的一次修改,最后面的最新的一次修改,从链表尾部逆向操作可以恢复到数据最老的版本。在InnoDB中,与之相关的还有undo tablespace, undo segment, undo slot, undo log这几个概念。undo log是最小的粒度,所在的数据页称为undo page,然后若干个undo page构成一个undo slot。一个事务最多可以有两个undo slot,一个是insert undo slot, 用来存储这个事务的insert undo,里面主要记录了主键的信息,方便在回滚的时候快速找到这一行。另外一个是update undo slot,用来存储这个事务delete/update产生的undo,里面详细记录了被修改之前每一列的信息,便于在读请求需要的时候构造。1024个undo slot构成了一个undo segment。然后若干个undo segemnt构成了undo tablespace。
历史链表: insert undo可以在事务提交/回滚后直接删除,没有事务会要求查询新插入数据的历史版本,但是update undo则不可以,因为其他读请求可能需要使用update undo构建之前的历史版本。因此,在事务提交的时候,会把update undo加入到一个全局链表(history list)中,链表按照事务提交的顺序排序,保证最先提交的事务的update undo在前面,这样Purge线程就可以从最老的事务开始做清理。这个链表如果太长说明有很多记录没被彻底删除,也有很多undolog没有被清理,这个时候就需要去看一下是否有个长事务没提交导致Purge线程无法工作。在InnoDB具体实现上,history list其实只是undo segment维度的,全局的history list采用最小堆来实现,最小堆的元素是某个undo segment中最小事务no对应的undopage。当这个undolog被Purge清理后,通过history list找到次小的,然后替换掉最小堆元素中的值,来保证下次Purge的顺序的正确性。
回滚点:又称为savepoint,事务回滚的时候可以指定回滚点,这样可以保证回滚到指定的点,而不是回滚掉整个事务,对开发者来说,这是一个强大的功能。在InnoDB内部实现中,每打一个回滚点,其实就是保存一下当前的undo_no,回滚的时候直接回滚到这个undo_no点就可以了。
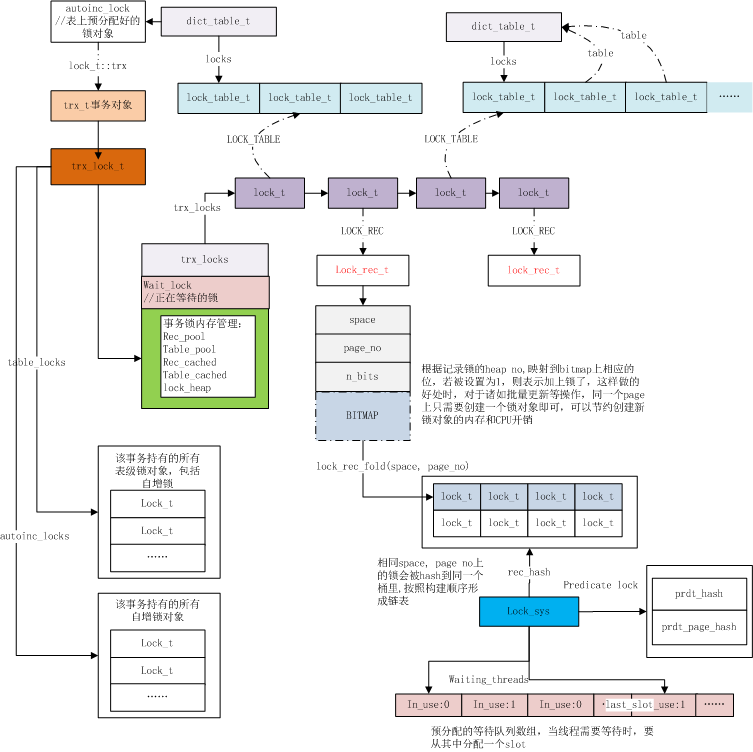
核心数据结构
在分析核心的代码之前,先介绍一下几个核心的数据结构。这些结构贯穿整个事务系统,理解他们对理解整个InnoDB的工作原理也颇有帮助。
trx_t:整个结构体每个连接持有一个,也就是在创建连接后执行第一个事务开始,整个结构体就被初始化了,后续这个连接的所有事务一直复用里面的数据结构,直到这个连接断开。同时,事务启动后,就会把这个结构体加入到全局事务链表中(trx_sys->mysql_trx_list),如果是读写事务,还会加入到全局读写事务链表中(trx_sys->rw_trx_list)。在事务提交的时候,还会加入到全局提交事务链表中(trx_sys->trx_serial_list)。state字段记录了事务四种状态:TRX_STATE_NOT_STARTED, TRX_STATE_ACTIVE, TRX_STATE_PREPARED, TRX_STATE_COMMITTED_IN_MEMORY。
这里有两个字段值得区分一下,分别是id和no字段。id是在事务刚创建的时候分配的(只读事务永远为0,读写事务通过一个全局id产生器产生,非0),目的就是为了区分不同的事务(只读事务通过指针地址来区分),而no字段是在事务提交前,通过同一个全局id生产器产生的,主要目的是为了确定事务提交的顺序,保证加入到history list中的update undo有序,方便purge线程清理。
此外,trx_t结构体中还有自己的read_view用来表示当前事务的可见范围。分配的insert undo slot和update undo slot。如果是只读事务,read_only也会被标记为true。
trx_sys_t:这个结构体用来维护系统的事务信息,全局只有一个,在数据库启动的时候初始化。比较重要的字段有:max_trx_id,这个字段表示系统当前还未分配的最小事务id,如果有一个新的事务,直接把这个值作为新事务的id,然后这个字段递增即可。descriptors,这个是一个数组,里面存放着当前所有活跃的读写事务id,当需要开启一个readview的时候,就从这个字段里面拷贝一份,用来判断记录的对事务的可见性。rw_trx_list,这个主要是用来存放当前系统的所有读写事务,包括活跃的和已经提交的事务。按照事务id排序,此外,奔溃恢复后产生的事务和系统的事务也放在上面。mysql_trx_list,这里面存放所有用户创建的事务,系统的事务和奔溃恢复后的事务不会在这个链表上,但是这个链表上可能会有还没开始的用户事务。trx_serial_list,按照事务no(trx_t->no)排序的已经提交的事务。rseg_array,这个指向系统所有可以用的回滚段(undo segments),当某个事务需要回滚段的时候,就从这里分配。rseg_history_len, 所有提交事务的update undo的长度,也就是上文提到的历史链表的长度,具体的update undo链表是存放在这个undo log中以文件指针的形式管理起来。view_list,这个是系统当前所有的readview, 所有开启的readview的事务都会把自己的readview放在这个上面,按照事务no排序。
trx_purge_t: Purge线程使用的结构体,全局只有一个,在系统启动的时候初始化。view,是一个readview,Purge线程不会尝试删除所有大于view->low_limit_no的undolog。limit,所有小于这个值的undolog都可以被truncate掉,因为标记的日志已经被删除且不需要用他们构建之前的历史版本。此外,还有rseg,page_no, offset,hdr_page_no, hdr_offset这些字段,主要用来保存最后一个还未被purge的undolog。
read_view_t: InnDB为了判断某条记录是否对当前事务可见,需要对此记录进行可见性判断,这个结构体就是用来辅助判断的。每个连接都的trx_t里面都有一个readview,在事务需要一致性的读时候(不同隔离级别不同),会被初始化,在读结束的时候会释放(缓存)。low_limit_no,这个主要是给purge线程用,readview创建的时候,会把当前最小的提交事务id赋值给low_limit_no,这样Purge线程就可以把所有已经提交的事务的undo日志给删除。low_limit_id, 所有大于等于此值的记录都不应该被此readview看到,可以理解为high water mark。up_limit_id, 所有小于此值的记录都应该被此readview看到,可以理解为low water mark。descriptors, 这是一个数组,里面存了readview创建时候所有全局读写事务的id,除了事务自己做的变更外,此readview应该看不到descriptors中事务所做的变更。view_list,每个readview都会被加入到trx_sys中的全局readview链表中。
trx_id_t:每个读写事务都会通过全局id产生器产生一个id,只读事务的事务id为0,只有当其切换为读写事务时候再分配事务id。为了保证在任何情况下(包括数据库不断异常恢复),事务id都不重复,InnoDB的全局id产生器每分配256(TRX_SYS_TRX_ID_WRITE_MARGIN)个事务id,就会把当前的max_trx_id持久化到ibdata的系统页上面。此外,每次数据库重启,都从系统页上读取,然后加上256(TRX_SYS_TRX_ID_WRITE_MARGIN)。
trx_rseg_t: undo segment内存中的结构体。每个undo segment都对应一个。update_undo_list表示已经被分配出去的正在使用的update undo链表,insert_undo_list表示已经被分配出去的正在使用的insert undo链表。update_undo_cached和insert_undo_cached表示缓存起来的undo链表,主要为了快速使用。last_page_no, last_offset, last_trx_no, last_del_marks表示这个undo segment中最后没有被Purge的undolog。
事务的启动
在InnoDB里面有两种事务,一种是读写事务,就是会对数据进行修改的事务,另外一种是只读事务,仅仅对数据进行读取。读写事务需要比只读事务多做以下几点工作:首先,需要分配回滚段,因为会修改数据,就需要找地方把老版本的数据给记录下来,其次,需要通过全局事务id产生器产生一个事务id,最后,把读写事务加入到全局读写事务链表(trx_sys->rw_trx_list),把事务id加入到活跃读写事务数组中(trx_sys->descriptors)。因此,可以看出,读写事务确实需要比只读事务多做不少工作,在使用数据库的时候尽可能把事务申明为只读。
start transaction语句启动事务。这种语句和begin work,begin等效。这些语句默认是以只读事务的方式启动。start transaction read only语句启动事务。这种语句就把thd->tx_read_only置为true,后续如果做了DML/DDL等修改数据的语句,会返回错误ER_CANT_EXECUTE_IN_READ_ONLY_TRANSACTION。start transaction read write语句启动事务。这种语句会把thd->tx_read_only置为true,此外,允许super用户在read_only参数为true的情况下启动读写事务。start transaction with consistent snapshot语句启动事务。这种启动方式还会进入InnoDB层,并开启一个readview。注意,只有在RR隔离级别下,这种操作才有效,否则会报错。
上述的几种启动方式,都会先去检查前一个事务是否已经提交,如果没有则先提交,然后释放MDL锁。此外,除了with consistent snapshot的方式会进入InnoDB层,其他所有的方式都只是在Server层做个标记,没有进入InnoDB做标记,在InnoDB看来所有的事务在启动时候都是只读状态,只有接受到修改数据的SQL后(InnoDB接收到才行。因为在start transaction read only模式下,DML/DDL都被Serve层挡掉了)才调用trx_set_rw_mode函数把只读事务提升为读写事务。
新建一个连接后,在开始第一个事务前,在InnoDB层会调用函数innobase_trx_allocate分配和初始化trx_t对象。默认的隔离级别为REPEATABLE_READ,并且加入到mysql_trx_list中。注意这一步仅仅是初始化trx_t对象,但是真正开始事务的是函数trx_start_low,在trx_start_low中,如果当前的语句只是一条只读语句,则先以只读事务的形式开启事务,否则按照读写事务的形式,这就需要分配事务id,分配回滚段等。
事务的提交
相比于事务的启动,事务的提交就复杂许多。这里只介绍事务在InnoDB层的提交过程,Server层涉及到与Binlog的XA事务暂时不介绍。入口函数为innobase_commit。
函数有一个参数commit_trx来控制是否真的提交,因为每条语句执行结束的时候都会调用这个函数,而不是每条语句执行结束的时候事务都提交。如果这个参数为true,或者配置了autocommit=1, 则进入提交的核心逻辑。否则释放因为auto_inc而造成的表锁,并且记录undo_no(回滚单条语句的时候用到,相关参数innodb_rollback_on_timeout)。
提交的核心逻辑:
- 依据参数innobase_commit_concurrency来判断是否有过多的线程同时提交,如果太多则等待。
- 设置事务状态为committing,我们可以在
show processlist看到(trx_commit_for_mysql)。 - 使用全局事务id产生器生成事务no,然后把事务trx_t加入到
trx_serial_list。如果当前的undo segment没有设置最后一个未Purge的undo,则用此事务no更新(trx_serialisation_number_get)。 - 标记undo,如果这个事务只使用了一个undopage且使用量小于四分之三个page,则把这个page标记为(
TRX_UNDO_CACHED)。如果不满足且是insert undo则标记为TRX_UNDO_TO_FREE,否则undo为update undo则标记为TRX_UNDO_TO_PURGE。标记为TRX_UNDO_CACHED的undo会被回收,方便下次重新利用(trx_undo_set_state_at_finish)。 - 把update undo放入所在undo segment的history list,并递增
trx_sys->rseg_history_len(这个值是全局的)。同时更新page上的TRX_UNDO_TRX_NO, 如果删除了数据,则重置delete_mark(trx_purge_add_update_undo_to_history)。 - 把undate undo从update_undo_list中删除,如果被标记为
TRX_UNDO_CACHED,则加入到update_undo_cached队列中(trx_undo_update_cleanup)。 - 在系统页中更新binlog名字和偏移量(
trx_write_serialisation_history)。 - mtr_commit,至此,在文件层次事务提交。这个时候即使crash,重启后依然能保证事务是被提交的。接下来要做的是内存数据状态的更新(
trx_commit_in_memory)。 - 如果是只读事务,则只需要把readview从全局readview链表中移除,然后重置trx_t结构体里面的信息即可。如果是读写事务,情况则复杂点,首先需要是设置事务状态为
TRX_STATE_COMMITTED_IN_MEMORY,其次,释放所有行锁,接着,trx_t从rw_trx_list中移除,readview从全局readview链表中移除,另外如果有insert undo则在这里移除(update undo在事务提交前就被移除,主要是为了保证添加到history list的顺序),如果有update undo,则唤醒Purge线程进行垃圾清理,最后重置trx_t里的信息,便于下一个事务使用。
事务的回滚
InnoDB的事务回滚是通过undolog来逆向操作来实现的,但是undolog是存在undopage中,undopage跟普通的数据页一样,遵循bufferpool的淘汰机制,如果一个事务中的很多undopage已经被淘汰出内存了,那么在回滚的时候需要重新把这些undopage从磁盘中捞上来,这会造成大量io,需要注意。此外,由于引入了savepoint的概念,事务不仅可以全部回滚,也可以回滚到某个指定点。
回滚的上层函数是innobase_rollback_trx,主要流程如下:
- 如果是只读事务,则直接返回。
- 判断当前是回滚整个事务还是部分事务,如果是部分事务,则记录下需要保留多少个undolog,多余的都回滚掉,如果是全部回滚,则记录0(trx_rollback_step)。
- 从update undo和insert undo中找出最后一条undo,从这条undo开始回滚(
trx_roll_pop_top_rec_of_trx)。 - 如果是update undo则调用
row_undo_mod进行回滚,标记删除的记录清理标记,更新过的数据回滚到最老的版本。如果是insert undo则调用row_undo_ins进行回滚,插入操作,直接删除聚集索引和二级索引。 - 如果是在奔溃恢复阶段且需要回滚的undolog个数大于1000条,则输出进度。
- 如果所有undo都已经被回滚或者回滚到了指定的undo,则停止,并且调用函数
trx_roll_try_truncate把undolog删除(由于不需要使用unod构建历史版本,所以不需要留给Purge线程)。 此外,需要注意的是,回滚的代码由于是嵌入在query graphy的框架中,因此有些入口函数不太好找。例如,确定回滚范围的是在函数trx_rollback_step中,真正回滚的操作是在函数row_undo_step中,两者都是在函数que_thr_step被调用。
多版本控制MVCC
数据库需要做好版本控制,防止不该被事务看到的数据(例如还没提交的事务修改的数据)被看到。在InnoDB中,主要是通过使用readview的技术来实现判断。查询出来的每一行记录,都会用readview来判断一下当前这行是否可以被当前事务看到,如果可以,则输出,否则就利用undolog来构建历史版本,再进行判断,知道记录构建到最老的版本或者可见性条件满足。
在trx_sys中,一直维护这一个全局的活跃的读写事务id(trx_sys->descriptors),id按照从小到大排序,表示在某个时间点,数据库中所有的活跃(已经开始但还没提交)的读写(必须是读写事务,只读事务不包含在内)事务。当需要一个一致性读的时候(即创建新的readview时),会把全局读写事务id拷贝一份到readview本地(read_view_t->descriptors),当做当前事务的快照。read_view_t->up_limit_id是read_view_t->descriptors这数组中最小的值,read_view_t->low_limit_id是创建readview时的max_trx_id,即一定大于read_view_t->descriptors中的最大值。当查询出一条记录后(记录上有一个trx_id,表示这条记录最后被修改时的事务id),可见性判断的逻辑如下(lock_clust_rec_cons_read_sees):
如果记录上的trx_id小于read_view_t->up_limit_id,则说明这条记录的最后修改在readview创建之前,因此这条记录可以被看见。
如果记录上的trx_id大于等于read_view_t->low_limit_id,则说明这条记录的最后修改在readview创建之后,因此这条记录肯定不可以被看家。
如果记录上的trx_id在up_limit_id和low_limit_id之间,且trx_id在read_view_t->descriptors之中,则表示这条记录的最后修改是在readview创建之时,被另外一个活跃事务所修改,所以这条记录也不可以被看见。如果trx_id不在read_view_t->descriptors之中,则表示这条记录的最后修改在readview创建之前,所以可以看到。
基于上述判断,如果记录不可见,则尝试使用undo去构建老的版本(row_vers_build_for_consistent_read),直到找到可以被看见的记录或者解析完所有的undo。
针对RR隔离级别,在第一次创建readview后,这个readview就会一直持续到事务结束,也就是说在事务执行过程中,数据的可见性不会变,所以在事务内部不会出现不一致的情况。针对RC隔离级别,事务中的每个查询语句都单独构建一个readview,所以如果两个查询之间有事务提交了,两个查询读出来的结果就不一样。从这里可以看出,在InnoDB中,RR隔离级别的效率是比RC隔离级别的高。此外,针对RU隔离级别,由于不会去检查可见性,所以在一条SQL中也会读到不一致的数据。针对串行化隔离级别,InnoDB是通过锁机制来实现的,而不是通过多版本控制的机制,所以性能很差。
由于readview的创建涉及到拷贝全局活跃读写事务id,所以需要加上trx_sys->mutex这把大锁,为了减少其对性能的影响,关于readview有很多优化。例如,如果前后两个查询之间,没有产生新的读写事务,那么前一个查询创建的readview是可以被后一个查询复用的。
垃圾回收Purge线程
Purge线程主要做两件事,第一,数据页内标记的删除操作需要从物理上删除,为了提高删除效率和空间利用率,由后台Purge线程解析undolog定期批量清理。第二,当数据页上标记的删除记录已经被物理删除,同时undo所对应的记录已经能被所有事务看到,这个时候undo就没有存在的必要了,因此Purge线程还会把这些undo给truncate掉,释放更多的空间。
Purge线程有两种,一种是Purge Worker(srv_worker_thread), 另外一种是Purge Coordinator(srv_purge_coordinator_thread),前者的主要工作就是从队列中取出Purge任务,然后清理已经被标记的记录。后者的工作除了清理删除记录外,还需要把Purge任务放入队列,唤醒Purge Worker线程,此外,它还要truncate undolog。
我们先来分析一下Purge Coordinator的流程。启动线程后,会进入一个大的循环,循环的终止条件是数据库关闭。在循环内部,首先是自适应的sleep,然后才会进入核心Purge逻辑。sleep时间与全局历史链表有关系,如果历史链表没有增长,且总数小于5000,则进入sleep,等待事务提交的时候被唤醒(srv_purge_coordinator_suspend)。退出循环后,也就是数据库进入关闭的流程,这个时候就需要依据参数innodb_fast_shutdown来确定在关闭前是否需要把所有记录给清除。接下来,介绍一下核心Purge逻辑。
- 首先依据当前的系统负载来确定需要使用的Purge线程数(
srv_do_purge),即如果压力小,只用一个Purge Cooridinator线程就可以了。如果压力大,就多唤醒几个线程一起做清理记录的操作。如果全局历史链表在增加,或者全局历史链表已经超过innodb_max_purge_lag,则认为压力大,需要增加处理的线程数。如果数据库处于不活跃状态(srv_check_activity),则减少处理的线程数。 - 如果历史链表很长,超过
innodb_max_purge_lag,则需要重新计算delay时间(不超过innodb_max_purge_lag_delay)。如果计算结果大于0,则在后续的DML中需要先sleep,保证不会太快产生undo(row_mysql_delay_if_needed)。 - 从全局视图链表中,克隆最老的readview,所有在这个readview开启之前提交的事务所产生的undo都被认为是可以清理的。克隆之后,还需要把最老视图的创建者的id加入到
view->descriptors中,因为这个事务修改产生的undo,暂时还不能删除(read_view_purge_open)。 - 从undo segment的最小堆中,找出最早提交事务的undolog(
trx_purge_get_rseg_with_min_trx_id),如果undolog标记过delete_mark(表示有记录删除操作),则把先关undopage信息暂存在purge_sys_t中(trx_purge_read_undo_rec)。 - 依据purge_sys_t中的信息,读取出相应的undo,同时把相关信息加入到任务队列中。同时更新扫描过的指针,方便后续truncate undolog。
- 循环第4步和第5步,直到全局历史链表为空,或者接下到view->low_limit_no,即最老视图创建时已经提交的事务,或者已经解析的page数量超过
innodb_purge_batch_size。 - 把所有的任务都放入队列后,就可以通知所有Purge Worker线程(如果有的话)去执行记录删除操作了。删除记录的核心逻辑在函数
row_purge_record_func中。有两种情况,一种是数据记录被删除了,那么需要删除所有的聚集索引和二级索引(row_purge_del_mark),另外一种是二级索引被更新了(总是先删除+插入新记录),所以需要去执行清理操作。 - 在所有提交的任务都已经被执行完后,就可以调用函数
trx_purge_truncate去删除update undo(insert undo在事务提交后就被清理了)。每个undo segment分别清理,从自己的histrory list中取出最早的一个undo,进行truncate(trx_purge_truncate_rseg_history)。truncate中,最终会调用fseg_free_page来清理磁盘上的空间。
事务的复活
在奔溃恢复后,也就是所有的前滚redo都应用完后,数据库需要做undo回滚,至于哪些事务需要提交,哪些事务需要回滚,这取决于undolog和binlog的状态。启动阶段,事务相关的代码逻辑主要在函数trx_sys_init_at_db_start中,简单分析一下。
- 首先创建管理undo segment的最小堆,堆中的元素是每个undo segment提交最早的事务id和相应undo segment的指针,也就是说通过这个元素可以找到这个undo segment中最老的未被Purge的undo。通过这个最小堆,可以找到所有undo segment中最老未被Purge的undo,方便Purge线程操作。
- 创建全局的活跃读写事务id数组。主要是给readview使用。
- 初始化所有的undo segment。主要是从磁盘读取undolog的内容,构建内存中的undo slot和undo segment,同时也构建每个undo segment中的history list,因为如果是fast shutdown,被标记为删除的记录可能还没来得及被彻底清理。此外,也构建每个undo segment中的inset_undo_list和update_undo_list,理论上来说,如果数据库关闭的时候所有事务都正常提交了,这两个链表都为空,如果数据库非正常关闭,则链表非空(
trx_undo_mem_create_at_db_start,trx_rseg_mem_create)。 - 从系统页里面读取max_trx_id,然后加上TRX_SYS_TRX_ID_WRITE_MARGIN来保证trx_id不会重复,即使在很极端的情况下。
- 遍历所有的undo segment,针对每个undo segment,分别遍历inset_undo_list和update_undo_list,依据undo的状态来复活事务。
- insert/update undo的处理逻辑:如果undolog上的状态是
TRX_UNDO_ACTIVE,则事务也被设置为TRX_STATE_ACTIVE,如果undolog上的状态是TRX_UNDO_PREPARED,则事务也被设置为TRX_UNDO_PREPARED(如果force_recovery不为0,则设置为TRX_STATE_ACTIVE)。如果undolog状态是TRX_UNDO_CACHED,TRX_UNDO_TO_FREE,TRX_UNDO_TO_PURGE,那么都任务事务已经提交了(trx_resurrect_insert和trx_resurrect_update)。 - 除了从undolog中复活出事务的状态信息,还需要复活出当前的锁信息(
trx_resurrect_table_locks),此外还需要把事务trx_t加入到rw_trx_list中。 - 所有事务信息复活后,InnoDB会做个统计,告诉你有多少undo需要做,因此可以在错误日志中看到类似的话: InnoDB: 120 transaction(s) which must be rolled back or cleaned up. InnoDB: in total 20M row operations to undo。
- 如果事务中操作了数据字典,比如创建删除表和索引,则这个事务会在奔溃恢复结束后直接回滚,这个是个同步操作,会延长奔溃恢复的时间(
recv_recovery_from_checkpoint_finish)。如果事务中没有操作数据字典,则后台会开启一个线程,异步回滚事务,所以我们常常发现,在数据库启动后,错误日志里面依然会有很多事务正在回滚的信息。
事务运维相关命令和参数
首先介绍一下information_schema中的三张表: innodb_trx, innodb_locks和innodb_lock_waits。由于这些表几乎需要查询所有事务子系统的核心数据结构,为了减少查询对系统性能的影响,InnoDB预留了一块内存,内存里面存了相关数据的副本,如果两次查询的时间小于0.1秒(
CACHE_MIN_IDLE_TIME_US),则访问的都是同一个副本。如果超过0.1秒,则这块内存会做一次更新,每次更新会把三张表用到的所有数据统一更新一遍,因为这三张表经常需要做表连接操作,所以一起更新能保证数据的一致性。这里简单介绍一下innodb_trx表中的字段,另外两张表涉及到事物锁的相关信息,由于篇幅限制,后续有机会在介绍。trx_id: 就是trx_t中的事务id,如果是只读事务,这个id跟trx_t的指针地址有关,所以可能是一个很大的数字(
trx_get_id_for_print)。trx_weight: 这个是事务的权重,计算方法就是undolog数量加上事务已经加上锁的数量。在事务回滚的时候,优先选择回滚权重小的事务,有非事务引擎参与的事务被认为权重是最大的。
trx_rows_modified:这个就是当前事务已经产生的undolog数量,每更新一条记录一次,就会产生一条undo。
trx_concurrency_tickets: 每次这个事务需要进入InnoDB层时,这个值都会减一,如果减到0,则事务需要等待(压力大的情况下)。
trx_is_read_only: 如果是以
start transaction read only启动事务的,那么这个字段是1,否则为0。trx_autocommit_non_locking: 如果一个事务是一个普通的select语句(后面没有跟for update, share lock等),且当时的autocommit为1,则这个字段为1,否则为0。
trx_state: 表示事务当前的状态,只能有
RUNNING,LOCK WAIT,ROLLING BACK,COMMITTING这几种状态, 是比较粗粒度的状态。trx_operation_state: 表示事务当前的详细状态,相比于trx_state更加详细,例如有
rollback to a savepoint,getting list of referencing foreign keys,rollback of internal trx on stats tables,dropping indexes等。与事务相关的undo参数
innodb_undo_directory: undo文件的目录,建议放在独立的一块盘上,尤其在经常有大事务的情况下。
innodb_undo_logs: 这个是定义了undo segment的个数。在给读写事务分配undo segment的时候,拿这个值去做轮训分配。
Innodb_available_undo_logs: 这个是一个status变量,在启动的时候就确定了,表示的是系统上分配的undo segment。举个例子说明其与innodb_undo_logs的关系:假设系统初始化的时候innodb_undo_logs为128,则在文件上一定有128个undo segment,Innodb_available_undo_logs也为128,但是启动起来后,innodb_undo_logs动态被调整为100,则后续的读写事务只会使用到前100个回滚段,最后的20多个不会使用。
innodb_undo_tablespaces: 存放undo segment的物理文件个数,文件名为undoN,undo segment会比较均匀的分布在undo tablespace中。
与Purge相关的参数
innodb_purge_threads: Purge Worker和Purge Coordinator总共的个数。在实际的实现中,使用多少个线程去做Purge是InnoDB根据实时负载进行动态调节的。
innodb_purge_batch_size: 一次性处理的undolog的数量,处理完这个数量后,Purge线程会计算是否需要sleep。
innodb_max_purge_lag: 如果全局历史链表超过这个值,就会增加Purge Worker线程的数量,也会使用sleep的方式delay用户的DML。
innodb_max_purge_lag_delay: 这个表示通过sleep方式delay用户DML最大的时间。
与回滚相关的参数
innodb_lock_wait_timeout: 等待行锁的最大时间,如果超时,则会滚当前语句或者整个事务。发生回滚后返回类似错误:Lock wait timeout exceeded; try restarting transaction。
innodb_rollback_on_timeout: 如果这个参数为true,则当发生因为等待行锁而产生的超时时,回滚掉整个事务,否则只回滚当前的语句。这个就是隐式回滚机制。主要是为了兼容之前的版本。
总结
本文简单介绍了InnoDB事务子系统的几个核心模块,在MySQL 5.7上,事务模块还有很多特性,例如高优先级事务,事务对象池等。与事务相关的还有事务锁系统,由于篇幅限制,本文不介绍,详情可以参考本期月报的这篇。此外,在阿里云最新发布的POLARDB for MySQL的版本中,由于涉及到共享存储架构,我们对事务子系统又进行了大量的改造,后续的月报会详细介绍。

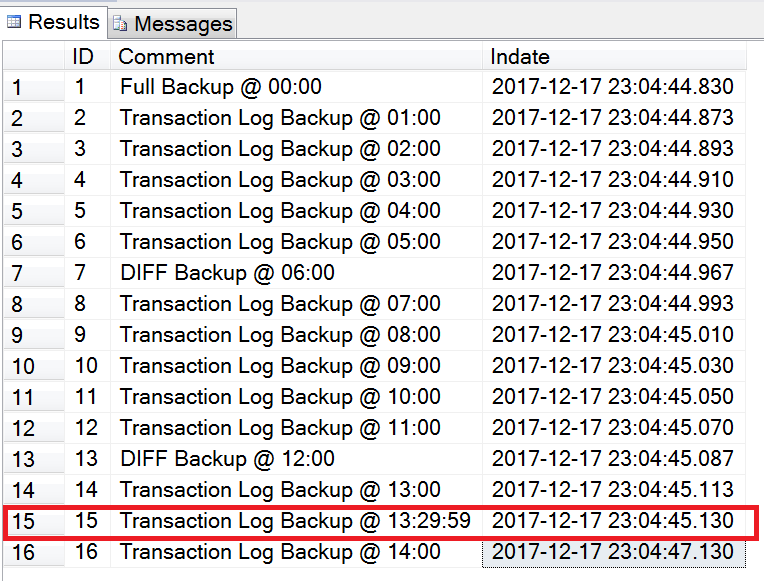

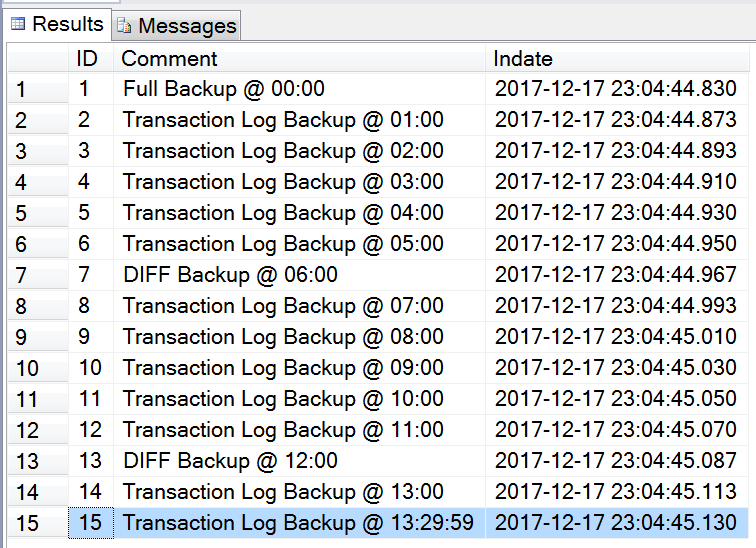
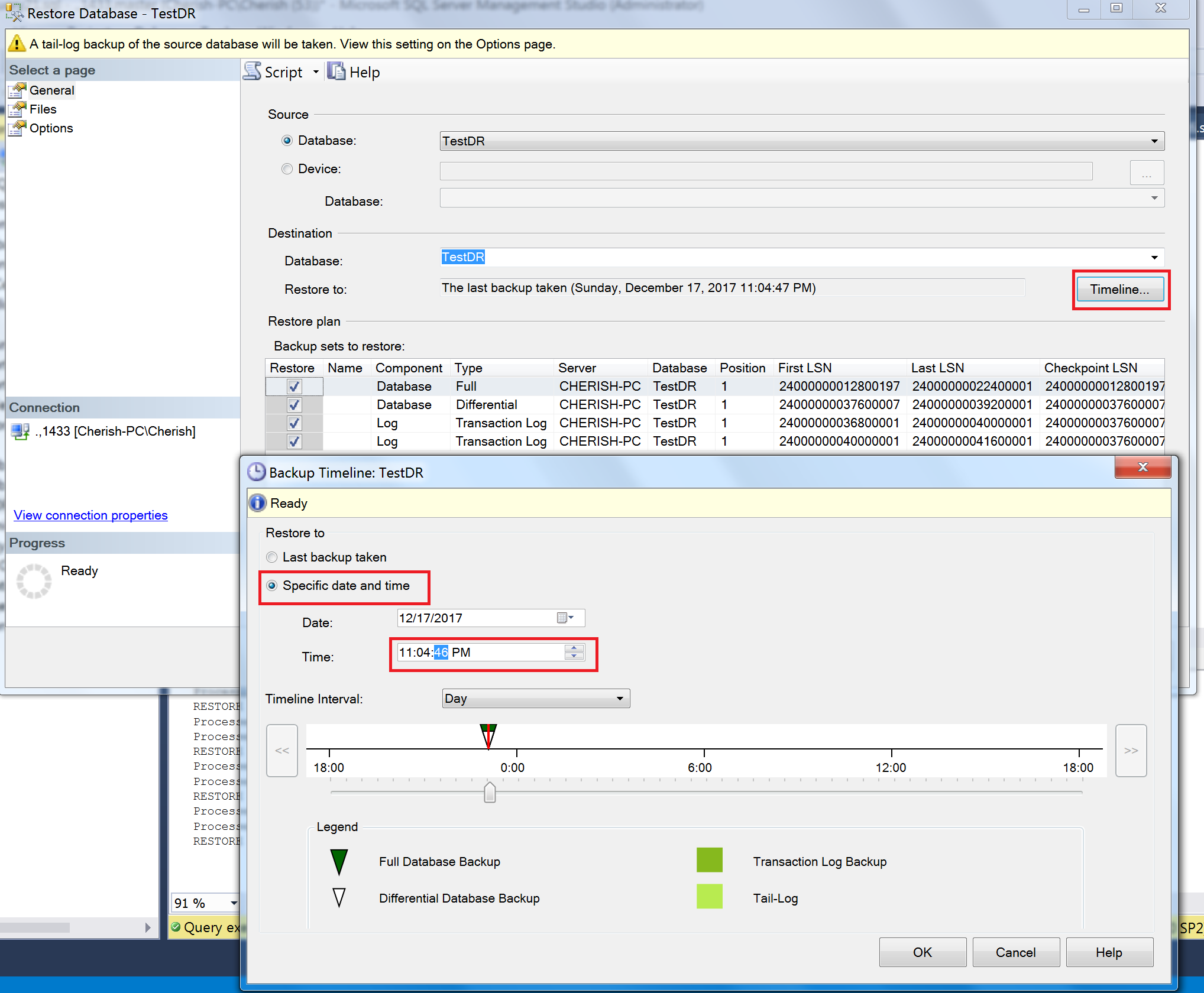
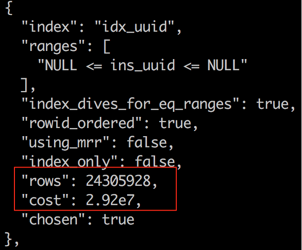
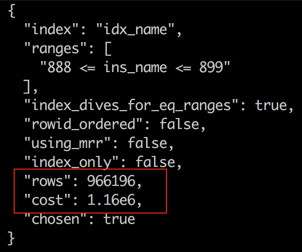
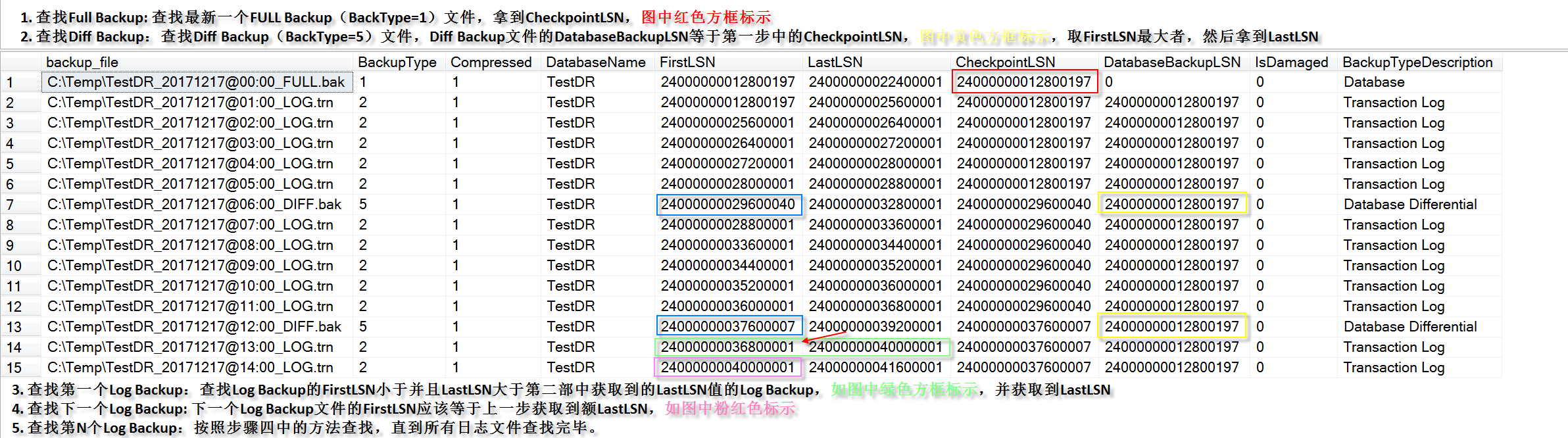
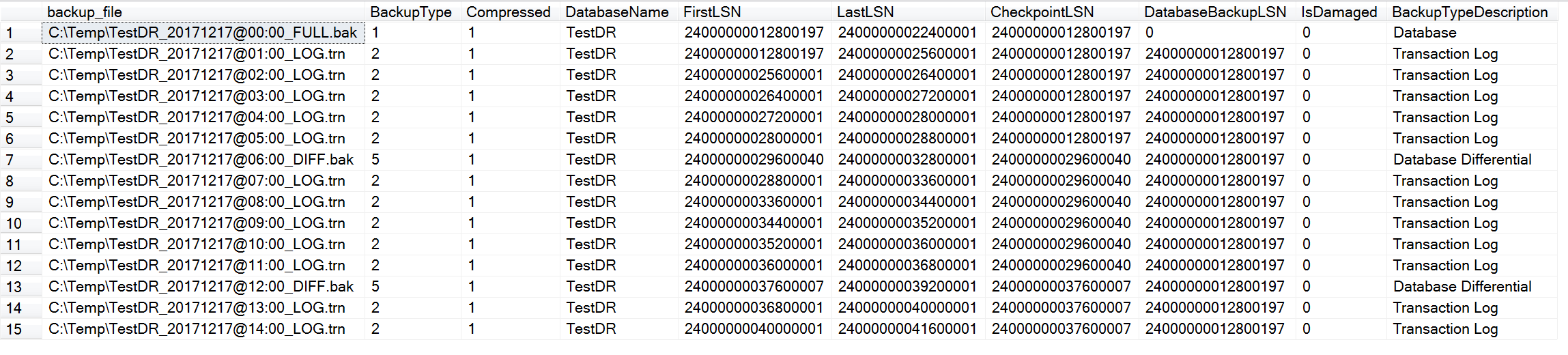
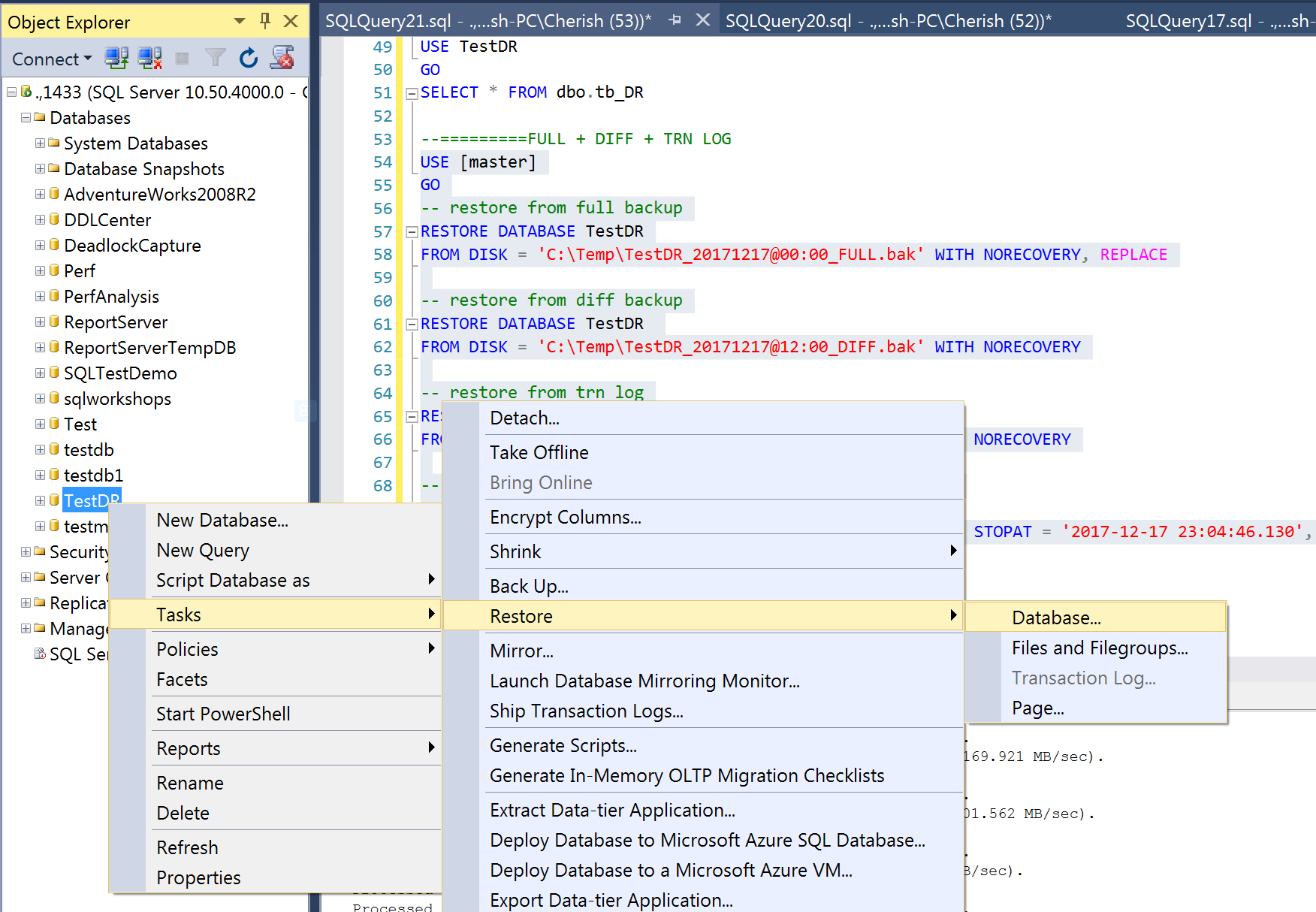 选择Timeline => Specific date and time => 设置你需要还原到的时间点(这里选择2017-12-17 23:04:46) => 确定。
选择Timeline => Specific date and time => 设置你需要还原到的时间点(这里选择2017-12-17 23:04:46) => 确定。
 时间点恢复还原时间消耗取决于你数据库备份文件的大小,在我的例子中,一会功夫,就已经还原好你想要的数据库了。
时间点恢复还原时间消耗取决于你数据库备份文件的大小,在我的例子中,一会功夫,就已经还原好你想要的数据库了。 这是很奇怪的,
这是很奇怪的,














![[LoliHouse] Princess-Session Orchestra - 15 [WebRip 1080p HEVC-10bit...](http://s2.loli.net/2025/04/09/QO618K72ytGZmDJ.webp)







